Contract Analyzer Series — Blog 1: Architecture & The $40K Problem#
A mid-tier law firm charges between $6,000 and $40,000 to review a 50-page SaaS agreement. Most of that cost isn't judgment — it's the first pass.
Reading every clause. Mapping each one to a category. Flagging the missing ones. Producing a summary a partner can skim in ten minutes. I've been through this process on vendor agreements for my own projects — the PDF goes to outside counsel, the clock starts, and a week later you get a 15-page memo that tells you the liability cap is mutual and there's no data processing addendum. First-pass work is exactly the kind of cognitive labor an LLM is good at. So I built a contract analyzer that does it in 25 seconds and costs $0.005 per run.
This series documents the architecture, the extraction pipeline, the risk scoring math, the streaming UX, and the frontend design decisions that make the output legible to a legal audience.
The Contract Analyzer Series#
| Part | Title | Focus |
|---|---|---|
| 1 | Architecture & The $40K Problem (this post) | System design, CUAD taxonomy, tech stack, pipeline |
| 2 | Clause Extraction with Closed-Vocabulary Prompting | Prompt engineering, 41 clause types, defensive JSON parsing |
| 3 | Risk Scoring & the Two-Call LLM Pipeline | Multi-stage orchestration, grounding, persona engineering |
| 4 | Streaming Progress with Server-Sent Events | SSE over POST, keepalives, AI UX for perceived latency |
| 5 | Legal-Tech Frontend & AI Trust UX | Design for skepticism, grounding, SVG gauge, dark/light theme |
The SA-Pro Portfolio: Build -> Optimize -> Monitor -> Apply to Domain x 2#
This is the fifth project in a portfolio arc that follows a deliberate progression:
| Series | Project | Question Answered |
|---|---|---|
| Deep Research Agent | Build | How do you build a multi-agent research pipeline? |
| Context Engine | Optimize | How do you reduce token waste by 34%? |
| Agent Observability | Monitor | How do you see what your agent is actually doing? |
| Clinical Research Agent | Healthcare Domain | How do you adapt AI for safety-critical medicine? |
| Contract Analyzer (this series) | Legal Domain | How do you apply AI to document-heavy business processes? |
Why Contract Review Is Different from Chat#
Contract review is not a chat problem. It is a classification problem with a fixed, enumerated output space.
When I first prototyped this, my instinct was to use a tool-calling agent loop — similar to the clinical research agent I'd just finished. Let the model read the contract, pick clauses to investigate, reason about each one, and synthesize. That reflex was wrong.
Agents are for open-ended tasks with unknown stopping conditions. Contract review has a completely known output: exactly 41 clause categories, a risk score, an executive summary. There is nothing for an agent to decide — no branching, no tool selection, no search strategy. Wrapping a deterministic task in a tool loop adds latency (every turn is a round-trip), unpredictability (3 turns or 10?), and cost (every turn re-sends the full contract).
The second instinct is RAG. Every document-AI tutorial reaches for it: chunk the PDF, embed the chunks, retrieve the top-k for each clause type. Also wrong. RAG exists to bridge the gap between a user's question and a corpus too large for context. A 50-page SaaS contract is ~25,000 tokens. Claude Haiku 4.5's context window is 200,000 tokens. The whole document fits. Beyond that, clause classification is a whole-document task — a termination clause on page 42 can modify a liability clause on page 8. Chunking destroys those cross-references. When your data is smaller than your context window, RAG is overhead pretending to be architecture.
The right shape is a sequential pipeline: fixed stages, each a pure function or a single LLM call with a defined input and output. The intelligence lives inside individual prompts, not in orchestration between them.
The CUAD Dataset: Where the 41 Clauses Come From#
Once I committed to a closed-vocabulary classification pipeline, the next question was: whose vocabulary?
My first prompt draft said something like "read this contract and extract the important clauses." I ran it twice on the same contract and got two entirely different category sets. Open-ended generation prompts do not converge. Asking an LLM to "find the important things" is asking it to do classification and taxonomy creation simultaneously. It invents a new taxonomy for every document.
The fix is a fixed, enumerated set of categories the model classifies into. And someone had already done the work of building the right one.
The Contract Understanding Atticus Dataset (CUAD), released in 2021 by The Atticus Project, is 510 real commercial contracts annotated by experienced contract lawyers. It contains 13,000+ clause annotations and 41 clause categories that practicing lawyers actually check for when reviewing commercial agreements. I use it as the fixed output space for the classification prompt — the same way a supervised model uses a label set.
Here is the taxonomy as implemented in the backend, grouped into 7 risk categories for the dashboard:
CLAUSE_CATEGORIES = { "termination": [ "Termination For Convenience", "Termination For Cause", "Effect of Termination", ], "financial": [ "Revenue/Profit Sharing", "Price Restrictions", "Minimum Commitment", "Audit Rights", ], "liability": [ "Cap on Liability", "Indemnification", "Insurance", "Warranty Duration", ], "ip_confidentiality": [ "IP Assignment", "License Grant", "Non-Compete", "Non-Disparagement", "Confidentiality", "No-Solicit of Employees", ], "operational": [ "Change of Control", "Assignment", "Anti-Assignment", "Product/Service Levels", "Renewal Term", "Most Favored Nation", "Exclusivity", ], "governance": [ "Governing Law", "Dispute Resolution", "Arbitration", "Third Party Beneficiary", "Uncapped Liability", ], "data_compliance": [ "Data Protection", "GDPR", "Right to Audit", "Privacy/Data", ], }
| Category | What It Covers | Why It Matters |
|---|---|---|
| Termination | For Convenience, For Cause, Effect of Termination | Can you exit without penalty? |
| Financial | Revenue Sharing, Price Restrictions, Audit Rights | Who pays what, when? |
| Liability | Cap on Liability, Indemnification, Insurance | How exposed are you? |
| IP & Confidentiality | IP Assignment, License Grant, Non-Compete, NDA | Who owns what? |
| Operational | Change of Control, Assignment, Auto-Renewal | Can the deal survive M&A? |
| Governance | Governing Law, Dispute Resolution, Arbitration | Where do you fight? |
| Data & Compliance | Data Protection, GDPR, Right to Audit | Regulatory exposure |
The subtler insight: most contract risk lives in clauses that are not there. A contract without a liability cap is a worse signal than one with a medium-risk cap. A closed taxonomy is the only way to reason about absence — you can only ask "is the liability cap missing" if you have a fixed list of things to check. Open-ended prompts can't detect absence at all.
Architecture Overview#
The pipeline that fell out of these decisions has five stages: parse, extract, score, find, summarize. Two of them are LLM calls. Three are deterministic Python.
User Uploads PDF
│
▼
┌─────────────────────────────────────────────────────┐
│ PDF PARSING (pdfplumber) │
│ Extract text from bytes → page_count, word_count │
└─────────────────────┬───────────────────────────────┘
│ SSE: "parsing" → "parsed"
▼
┌─────────────────────────────────────────────────────┐
│ CLAUSE EXTRACTION (Haiku 4.5 via Strands) │
│ One prompt, 41 CUAD clause types, temp=0.1 │
│ Full contract in context, no RAG │
│ → JSON array of clause classifications │
└─────────────────────┬───────────────────────────────┘
│ SSE: "extracting" → "extracted"
▼
┌─────────────────────────────────────────────────────┐
│ RISK SCORING (pure Python) │
│ Weighted average, non-linear risk levels │
│ Per-category missing-clause penalty │
│ → 0-100 score + 7-category breakdown │
└─────────────────────┬───────────────────────────────┘
│ SSE: "scoring" → "scored"
▼
┌─────────────────────────────────────────────────────┐
│ FINDINGS & RECOMMENDATIONS (pure Python) │
│ Rule-based patterns over clause + risk data │
└─────────────────────┬───────────────────────────────┘
│ SSE: "analyzing" → "analyzed"
▼
┌─────────────────────────────────────────────────────┐
│ EXECUTIVE SUMMARY (Haiku 4.5 via Strands) │
│ Second AI call — temp=0.3 for prose │
│ Input is clause list + risk score, NOT contract │
│ → 3-5 paragraph markdown summary │
└─────────────────────┬───────────────────────────────┘
│ SSE: "summarizing" → "complete"
▼
Structured Report
(streamed via SSE as events arrive)
Two AI calls, three deterministic Python stages, SSE progress events between every stage. Notice that the summary call's input is the clause list and risk score — not the original contract. The first call already turned the document into structured data. The second call operates over a few KB of JSON, not 80,000 characters of contract text. That's the key cost and latency saving in the two-call split.
Tech Stack#
| Component | Technology | Purpose |
|---|---|---|
| LLM | Claude Haiku 4.5 via Amazon Bedrock | Extraction and summary calls |
| Agent Framework | Strands SDK | Clean one-shot Agent(model, prompt) — no tool loop |
| PDF Parsing | pdfplumber | Pure Python, MIT, handles real contracts |
| Backend | Python 3.12 + FastAPI | StreamingResponse for SSE, UploadFile for multipart |
| Frontend | React 19 + TypeScript + Vite | Fast dev loop, modern patterns |
| Streaming | SSE over fetch + ReadableStream | Progress events without WebSockets |
| Styling | Tailwind CSS v4 | Theme switching via CSS variable overrides |
| Local Dev | Docker Compose | Hot reload, AWS credentials mounted from ~/.aws |
No vector database. No embedding model. No WebSocket server. No message queue. No state store beyond an in-memory dict keyed by analysis ID. The architecture is small because the decisions above eliminated every component a default document-AI tutorial would have added.
Model Selection: Why Claude Haiku 4.5#
My constraints, in priority order: JSON fidelity (the extraction call must return parseable JSON with 41 fields), latency (full analysis under 30 seconds), cost (under $0.02 per run so the two-call split doesn't hurt unit economics), context window (at least 100K tokens for the full contract plus schema), and reasoning quality sufficient for legal language.
Claude Haiku 4.5 satisfies all five. At approximately $0.25/M input and $1.25/M output tokens on Bedrock, a full analysis — two calls, ~20K tokens of contract input — costs roughly $0.005. Claude Sonnet 4.5 would have been ~$0.20 per analysis, 40x more, which would have made me squeamish about the two-call design. Haiku 4.5's 200K context window means the whole contract fits with headroom — no chunking, no truncation decisions.
The concern with smaller models is JSON fidelity. Haiku 4.5 is the generation where that stopped being a real problem for me. With a well-structured prompt and a bracket-slicing defensive parser, I hit 100% successful parses on every contract I tested — well enough that I never had to reach for Bedrock's JSON mode or function calling. That matters because function calling adds tool schema to the prompt, eats tokens, and slows responses. Skip it when you can.
Latency lands at 8-14 seconds for the extraction call on a 50-page contract, 3-6 seconds for the summary call. Total pipeline: 20-30 seconds. The point is not that Haiku is "good enough" — it's that it's the right envelope for this task. Model selection is about constraints, not leaderboards.
The Two-Call Pipeline (Classification + Generation)#
Classification and prose generation are two different cognitive tasks. They want opposite things from the model.
My first prototype used a single LLM call: one prompt, one big structured JSON with a clauses field and a summary field. The clause extraction was fine. The executive summary was robotic and hedged — "it should be noted that the agreement contains provisions which may be considered." I spent an hour tuning the prompt. Every tweak that improved the summary degraded the extraction. The model started hallucinating clause names, skipping JSON fields, wrapping output in conversational preamble.
The issue is that the two tasks need opposite sampling configurations:
| Task | Temperature | Output | Cognitive mode |
|---|---|---|---|
| Clause extraction | 0.1 | Structured JSON | Deterministic, exhaustive, literal |
| Executive summary | 0.3 | Prose Markdown | Fluent, selective, opinionated |
When one prompt does two kinds of cognitive work, split them. The extraction call runs at temperature=0.1, max_tokens=8192, full contract in context. The summary call runs at temperature=0.3, max_tokens=2048, with the classified clause list and computed risk score as its only input — not the contract.
The unit of a prompt is a single cognitive task. If you can describe your prompt as "the model should do A and then B," you have two prompts. Split them.
Full orchestration, scoring math, missing-clause penalty, and the summary prompt are in Blog 3.
Configuration#
The configuration is minimal by design. Here is the full config.py:
import os from pathlib import Path # AWS / Bedrock AWS_REGION = os.getenv("AWS_REGION", "us-east-1") BEDROCK_MODEL_ID = os.getenv( "BEDROCK_MODEL_ID", "us.anthropic.claude-haiku-4-5-20251001-v1:0" ) # App CORS_ORIGINS = os.getenv("CORS_ORIGINS", "http://localhost:5173").split(",") MAX_FILE_SIZE_MB = int(os.getenv("MAX_FILE_SIZE_MB", "10")) SAMPLES_DIR = Path(os.getenv("SAMPLES_DIR", "samples"))
No Pydantic Settings, no .env loader, no class hierarchy. Five variables. The only external dependency is Bedrock for LLM inference — no DynamoDB, no S3, no other AWS services.
The Docker Compose setup mounts AWS credentials from the host so you don't need to bake them into the container:
services: backend: build: ./backend ports: - "8000:8000" volumes: - ~/.aws:/root/.aws:ro environment: - AWS_PROFILE=${AWS_PROFILE:-default} - AWS_REGION=us-east-1 command: uvicorn app.main:app --host 0.0.0.0 --port 8000 --reload frontend: build: ./frontend ports: - "5173:5173" environment: - VITE_API_URL=http://localhost:8000 command: npm run dev -- --host
The :ro mount on ~/.aws is deliberate. The container needs read access to your credentials file, not write access.
The Frontend State Machine#
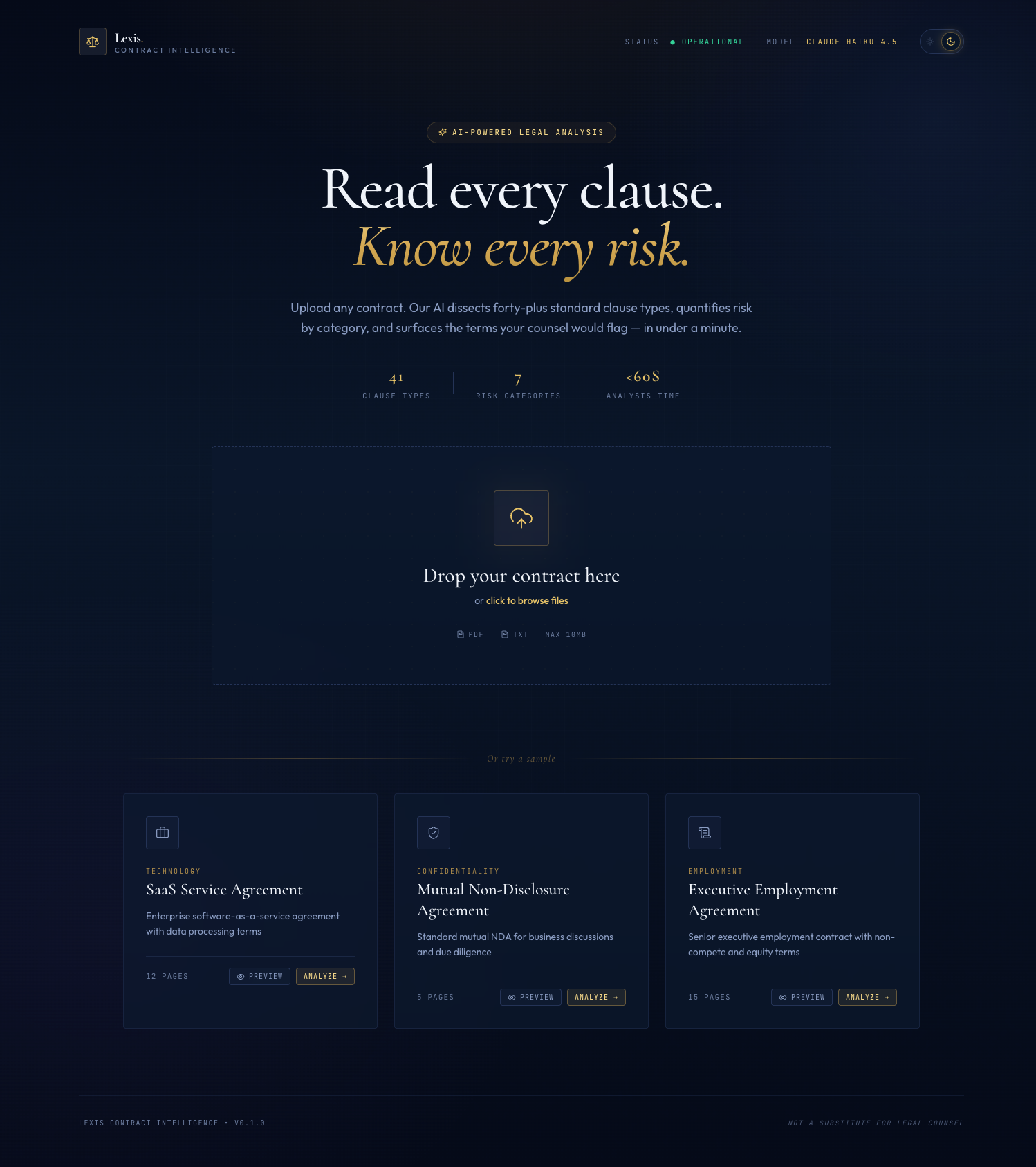
The frontend has three states: upload, loading, and dashboard. The upload state is a single drag-drop zone — no chat history, no sidebar, no configuration panel. The user drags a PDF and the analysis starts.
During loading, the UI renders a step-by-step timeline that mirrors the pipeline stages: Parsing document, Extracting clauses, Scoring risk, Analyzing findings, Generating summary. Each step resolves as the corresponding SSE progress event arrives from the backend. The user sees cognitive work happen in real time rather than staring at a spinner for 25 seconds.
The dashboard renders the risk score as a custom SVG gauge, the 7-category breakdown as a horizontal bar chart, the clause list grouped by category with presence/absence indicators, and the executive summary in Markdown. The design uses Cormorant serif headings and a deep navy palette to signal "legal document," not "SaaS demo." That design decision is covered fully in Blog 5.
Real Cost Numbers#
The case for this architecture is economic before it is technical.
| Analysis type | Cost | Time |
|---|---|---|
| AI contract analyzer (this system) | ~$0.005 | 20-30 seconds |
| Paralegal first pass | $75-$150/hour, ~2-4 hours | 2-4 hours |
| Mid-tier law firm full review | $6,000-$40,000 | 5-10 business days |
At $0.005 per analysis, you could run every vendor agreement through this pipeline for less than the cost of a single paralegal hour per year. The system does not replace a lawyer's judgment. It replaces the first pass — the reading, categorizing, and missing-clause detection that happens before a lawyer can apply judgment. That first pass is what most of the cost is.
The five-orders-of-magnitude cost difference is achievable because the pipeline is deterministic in shape, uses a small fast model well-suited to the task, and avoids every piece of infrastructure that a default document-AI architecture would have added.
What's Next#
In Blog 2: Clause Extraction with Closed-Vocabulary Prompting, we'll build the prompt that reliably classifies all 41 CUAD clause types in a single Claude Haiku call — with schema-first design, temperature discipline, and defensive JSON parsing for when the model misbehaves.
This is post 1 of 5 in the Contract Analyzer Series. The full series covers architecture, clause extraction, risk scoring, streaming UX, and legal-tech frontend design for an AI-powered contract analyzer.
All code is open source: github.com/MinhQuanBuiSco/contract-analyzer