Contract Analyzer Series — Blog 3: Risk Scoring & the Two-Call LLM Pipeline#
Turning 35 classified clauses into a single trustworthy risk score sounds like a job for AI — it isn't.
In Part 2 the pipeline ended with a list[dict] of 35 classified clauses. That is structured data. It is not yet a product. A user wants to know one thing first: is this contract risky. They want a single number, a one-paragraph verdict, and a place to drill in.
My first attempt asked Claude to compute the score. The result was non-deterministic, 10x slower than Python math, impossible to audit, and the same contract scored 27, 31, and 33 on three successive runs — a disqualifying bug in a legal product. I deleted that call and rewrote the function as 30 lines of Python. But that Python had its own problems. A simple average hid the most dangerous clauses behind a wall of low-risk boilerplate. Fixing the math — through non-linear weights, category weights, and missing-clause penalties — is the main story of this post. The second story is the executive summary: the one thing deterministic code genuinely cannot produce. That required a second AI call, with a completely different persona, temperature, and input format than the extraction call. Splitting those two jobs apart was the single biggest quality improvement in the whole backend.
The Contract Analyzer Series#
| Part | Title | Focus |
|---|---|---|
| 1 | Architecture & The $40K Problem | System design, CUAD taxonomy, tech stack, pipeline |
| 2 | Clause Extraction with Closed-Vocabulary Prompting | Prompt engineering, 41 clause types, defensive JSON parsing |
| 3 | Risk Scoring & the Two-Call LLM Pipeline (this post) | Multi-stage orchestration, grounding, persona engineering |
| 4 | Streaming Progress with Server-Sent Events | SSE over POST, keepalives, AI UX for perceived latency |
| 5 | Legal-Tech Frontend & AI Trust UX | Design for skepticism, grounding, SVG gauge, dark/light theme |
The Problem: From 35 Clauses to One Number#
The naive approach is a simple average. Map risk levels to numbers (low=0, medium=33, high=66, critical=100), average across all found clauses, and call it the score:
# Version 1 — do not do this weights = {"low": 0, "medium": 33, "high": 66, "critical": 100} found = [c for c in clauses if c["found"]] score = sum(weights[c["risk_level"]] for c in found) / len(found)
Running this against the Mutual NDA gave me 14/100 — Low Risk. That is wrong. The NDA has a high-risk Dispute Resolution clause that locks venue to Santa Clara County, and it is completely missing a Cap on Liability — the single most important protective term in any commercial agreement. But because seven other low-risk clauses dragged down the average, the math hid both problems.
Before fixing the Python, I should mention: the version before this Python attempt was an LLM call. I asked Claude to compute the score from the clause list and return JSON. It worked. Sort of. The same contract scored 27, 31, and 33 on three successive runs. Non-determinism is a product-killing bug for a legal tool. I deleted that call and wrote the function as pure Python — deterministic, a millisecond of runtime, every number traceable back to a constant at the top of the module.
The average had three specific problems built in, and each one became a step.
Step 1: Risk Weights#
The even-spacing assumption is wrong. low → medium is "standard clause → slightly one-sided." high → critical is "heavily favors them → do not sign." The latter jump is a much bigger deal. A critical clause is a deal-breaker; a medium clause is a negotiation point.
The fix was non-linear weights with compressed low end and expanded high end:
RISK_WEIGHTS = { "low": 0, "medium": 25, "high": 65, "critical": 100, }
low → medium is +25. medium → high is +40. high → critical is +35. That asymmetry reflects how legal risk actually scales. Going from a standard clause to a slightly one-sided one is a negotiation point. Going from a bad clause to a deal-breaker is a categorically different situation — the weight spacing needs to reflect that.
These are constants at the top of the module. A legal team can override any of them in one line. That is something you cannot do to a prompt buried in an LLM call.
Step 2: Category Weights#
Even with non-linear clause weights, treating all categories equally is wrong. A high-risk Governing Law clause ("governed by Delaware law" when you are in New York) is annoying — you have to fly to Wilmington for court. A high-risk Cap on Liability clause ("no liability above $1M" on a $50M deal) is existential. Both are "high-risk clauses." They should not contribute equally to the overall score.
Category weights layer on top of clause weights to handle this:
CATEGORY_WEIGHTS = { "Liability": 1.4, # Highest — existential risk "Financial": 1.3, # Money you have to pay "Termination": 1.2, # Exit rights "IP & Confidentiality": 1.1, "Data & Compliance": 1.0, # Baseline — regulatory exposure "Operational": 0.9, # Rarely catastrophic "Governance": 0.8, # Inconvenient, not fatal }
All weights are centered around 1.0. Liability is 1.4x because unlimited liability is existential — it can end a company. Governance is 0.8x because at worst it means inconvenient travel to a different jurisdiction's courthouse.
These are my opinions based on reading real contract disputes, not objective truths. A financial services company would probably rate Data & Compliance at 1.5+. But they are constants at the top of a module, overridable in one line. That is something you cannot do to a prompt.
Step 3: The Scoring Function#
The third problem with the naive average was that it calculated risk only from present clauses. A contract missing its liability cap just had fewer items in the sum — which made it look safer. But absence is itself a risk signal. A contract that says nothing about liability exposes both parties to unlimited damages by default. A contract with five low-risk found clauses and thirty missing clauses would score 0/100 under naive math, when it is actually one of the most dangerous situations possible.
The fix was a missing-clause penalty inside the per-category calculation:
def calculate_risk_score(clauses: list[dict]) -> dict: category_data = defaultdict(list) for clause in clauses: category_data[clause["category"]].append(clause) category_scores = {} weighted_total = 0.0 total_weight = 0.0 for category, cat_clauses in category_data.items(): found_clauses = [c for c in cat_clauses if c["found"]] missing_clauses = [c for c in cat_clauses if not c["found"]] # Score from found clauses if found_clauses: risk_points = [RISK_WEIGHTS[c["risk_level"]] for c in found_clauses] avg_risk = sum(risk_points) / len(risk_points) else: avg_risk = 30 # "We don't know what's in this category" — moderate # Missing clause penalty missing_risk = len(missing_clauses) * 15 cat_score = min(100, avg_risk + (missing_risk / max(len(cat_clauses), 1))) weight = CATEGORY_WEIGHTS.get(category, 1.0) weighted_total += cat_score * weight total_weight += weight overall_score = round(weighted_total / max(total_weight, 1), 1) # ... build and return the result dict
Three details worth naming.
Per-category, not global penalty. If Liability has 4 clauses and 3 are missing, the penalty is (3 * 15) / 4 = 11.25. Bounded and proportional. A contract missing all liability clauses is worse than one missing one of four — the math reflects that.
avg_risk = 30 fallback. When a category has zero found clauses, 0 says "all clear" and 100 says "all risk" — both wrong. 30 says "we don't know what is in this category" — moderate, not safe, not catastrophic. It is a deliberate statement of uncertainty.
min(100, ...) cap keeps outputs interpretable. The maximum is always "critical risk," never "impossibly critical."
Running this against the Mutual NDA produces:
{ "overall_score": 30.7, "overall_label": "Medium Risk", "category_scores": { "Governance": {"score": 55.0, "label": "High Risk", ...}, "Liability": {"score": 45.0, "label": "Medium Risk", ...}, "Financial": {"score": 45.0, "label": "Medium Risk", ...}, # ... } }
30.7/100 — Medium Risk. That is the right answer. One high-risk clause drives Governance up, missing liability clauses pull Liability to 45 through the penalty, and seven low-risk protections keep the overall out of High Risk territory.
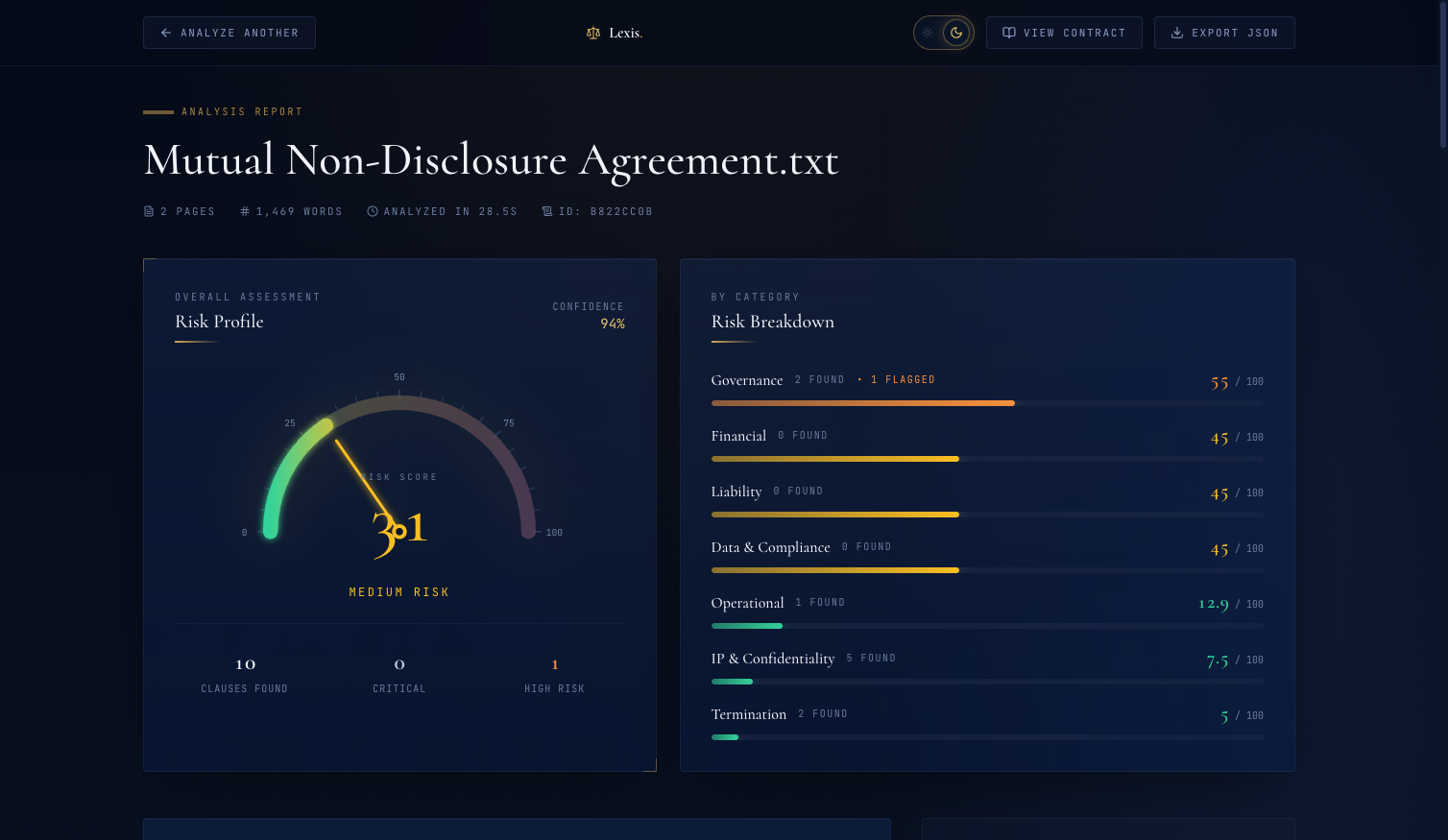 The gauge reads 31/100 — Medium Risk. Governance is highest (the venue lock). Liability is tied for second despite zero found clauses — entirely from the missing-clause penalty.
The gauge reads 31/100 — Medium Risk. Governance is highest (the venue lock). Liability is tied for second despite zero found clauses — entirely from the missing-clause penalty.
Total runtime: under one millisecond. Total cost: zero. Deterministic, auditable, editable.
Step 4: Key Findings & Recommendations (No AI Required)#
Key Findings and Recommendations are another place where it is tempting to reach for AI and wrong to do it. Both are pattern matches over structured data — exactly what Python is for:
def generate_key_findings(clauses: list[dict]) -> list[str]: findings = [] found = [c for c in clauses if c["found"]] findings.append( f"Identified {len(found)} out of {len(clauses)} standard clause types in this contract." ) risk_dist = Counter(c["risk_level"] for c in found) if risk_dist["critical"]: findings.append( f"{risk_dist['critical']} clause(s) flagged as CRITICAL risk — immediate attention required." ) if risk_dist["high"]: findings.append( f"{risk_dist['high']} clause(s) rated HIGH risk — negotiation recommended before signing." ) missing_liability = any( not c["found"] for c in clauses if c["clause_type"] in ("Cap on Liability", "Limitation of Liability") ) if missing_liability: findings.append( "WARNING: No liability cap or limitation found — potential for unlimited exposure." ) has_auto_renewal = any(c["found"] for c in clauses if c["clause_type"] == "Auto-Renewal") if has_auto_renewal: findings.append( "Contract includes auto-renewal — ensure cancellation terms are acceptable." ) return findings
This is a pattern that shows up across every serious AI pipeline: a rules layer downstream of the LLM that asserts invariants, produces human-readable artifacts from structured fields, and computes derived quantities. Cheap, fast, unit-testable. It is also the layer you reach for when you need to patch a specific failure mode the model keeps making. If clause classification started miscategorizing auto-renewal clauses, I could force the warning from here without touching the LLM.
Recommendations follow the same shape but are more prescriptive — they look at risk score thresholds and missing critical clauses to produce specific negotiation priorities. Zero AI calls, and that is the point. When the output is a deterministic function of structured inputs, Python is the right tool. The LLM does not need to be involved.
def generate_recommendations(clauses: list[dict], risk_data: dict) -> list[str]: recommendations = [] overall_score = risk_data.get("overall_score", 0) if overall_score >= 70: recommendations.append( "HIGH PRIORITY: Seek legal counsel before signing — multiple significant risk factors identified." ) elif overall_score >= 40: recommendations.append( "MODERATE: Review flagged clauses with counsel and negotiate key terms before execution." ) else: recommendations.append( "LOW RISK: Standard review recommended. Verify missing clauses are intentionally omitted." ) # Clause-specific recommendations for clause in clauses: if not clause["found"] and clause["clause_type"] == "Cap on Liability": recommendations.append( "NEGOTIATE: Add a mutual liability cap — absence creates unlimited exposure for both parties." ) if clause.get("found") and clause.get("risk_level") == "critical": recommendations.append( f"CRITICAL: '{clause['clause_type']}' requires immediate attention before signing." ) return recommendations
Step 5: The Second AI Call — Executive Summary#
Everything above produces structured data. But when a user opens the dashboard, the first thing they read is the Executive Summary: a few paragraphs of prose explaining the verdict in plain English. That is the one thing the rules approach genuinely cannot do. Weaving facts, emphasis, and a recommendation into natural prose is exactly what LLMs are built for.
So I added a second Claude call. The prompt is deliberately minimal — it receives structured output, not raw contract text:
SUMMARY_PROMPT = """Based on the following contract analysis results, write a concise executive summary (3-5 paragraphs). The summary should cover: 1. Overall risk assessment and what it means 2. Key areas of concern (high/critical risk clauses) 3. Notable missing protections 4. Overall recommendation (sign as-is, negotiate, or walk away) CONTRACT FILENAME: {filename} OVERALL RISK: {risk_label} ({risk_score}/100) CLAUSE ANALYSIS: {clause_summary} KEY FINDINGS: {findings} Write the summary in clear, professional language suitable for a business executive. Respond with ONLY the summary text, no JSON or formatting markers."""
Notice what is not in this prompt: the raw contract, the 41-clause schema, any of the rich legal prose the extraction call had to wade through. All gone. The summary call only sees the output of steps 1 through 4.
The function that builds and fires this call:
def _generate_executive_summary( filename: str, clauses: list[dict], risk_score: dict, key_findings: list[str], ) -> str: """Generate an executive summary using AI.""" found_clauses = [c for c in clauses if c.get("found")] clause_summary = "\n".join( f"- [{c['risk_level'].upper()}] {c['clause_type']}: {c['explanation']}" for c in found_clauses ) if not clause_summary: clause_summary = "No clauses were identified in the contract." findings_text = "\n".join(f"- {f}" for f in key_findings) prompt = SUMMARY_PROMPT.format( filename=filename, risk_label=risk_score["overall_label"], risk_score=risk_score["overall_score"], clause_summary=clause_summary, findings=findings_text, ) model = BedrockModel( model_id=BEDROCK_MODEL_ID, region_name=AWS_REGION, max_tokens=2048, temperature=0.3, ) agent = Agent( model=model, system_prompt=( "You are a senior legal analyst writing executive summaries " "for contract reviews." ), ) result = agent(prompt) return str(result)
Three serialization details worth calling out.
Markdown-ish bullets with bracketed tags, not JSON. I tried feeding the structured data as JSON. The output came back stilted and more likely to quote field names back at the user ("The clause_type 'Dispute Resolution' has a risk_level of 'high'..."). When you want prose output, feed the LLM a format that already resembles prose. JSON is for machines; markdown is for language models about to write.
Uppercase tags. [HIGH] is visually distinct from [high], and Claude leans on those tags to anchor paragraphs ("The high-risk dispute resolution clause..."). Small choice, real effect.
temperature=0.3, not 0.1 and not 0.7. The extraction call runs at 0.1 — classification wants determinism, and the same contract should produce the same 35 classifications every time. At 0.1 for the summary call, every summary started with "This contract presents a medium risk profile..." — every one, robotic and indistinguishable across contracts. Bumping to 0.3 gives the model room to vary sentence structure while keeping facts pinned to the structured input.
I tried 0.7. The model started inventing things: a "Section 8.3" that did not exist, a "force majeure clause" the contract did not have, a dollar figure ("liability capped at $500,000") from no clause I had ever passed it. Plausible but fictional. Catastrophic for a legal product. The scary part was how confidently they were written. At 0.7, hallucinations are indistinguishable from true statements unless you check them against the source. 0.3 is the narrow band where prose feels natural but stays anchored to the structured input. It took three rounds of experimentation to find it.
The system prompt persona is also different. The extraction call uses "You are a precise legal analysis AI. Always respond with valid JSON only." The summary call uses "You are a senior legal analyst writing executive summaries for contract reviews." Same model. Same Bedrock endpoint. Completely different voice. "Senior legal analyst" sets seniority (willing to give verdicts), "writing executive summaries" sets the output format, "for contract reviews" sets the domain. Every word is doing work. Generic personas produce hedged output; specific ones produce confident verdicts.
Why Two Calls, Not One#
My first attempt did extraction and summary in a single prompt:
Analyze this contract. Return: 1. A JSON array of clauses with risk levels 2. A 3-paragraph executive summary
Elegant on paper. Bad in two directions at once.
The clauses got shorter. The model silently rationed output tokens to leave room for the summary. Explanations shrank to fragments — "one-sided" or "standard" — that were useless for rendering the clause detail view.
The summary got stiff and templated. The model was in "structured mode" from the JSON earlier in the prompt and could not switch gears. Every summary came out identical: "This contract presents a medium risk profile. The clauses analyzed include..." The JSON parsing also got unreliable — the model would emit JSON, then prose, then fragments of more JSON, and my extraction logic could not find the right bracket pair.
One call was being asked to do two cognitive tasks with two incompatible surface forms. The lesson: when a single LLM call is handling structured reasoning and creative prose simultaneously, split them. Give each its own temperature, persona, and output format. The token cost is minimal; the quality improvement is dramatic.
Grounding Prevents Hallucination#
The summary call does not see the contract text. It only sees the structured output of the extraction call, the computed risk scores, and the rules-generated findings.
This is a grounding pattern — Retrieval-Augmented Generation in its simplest form. In classical RAG you use an embedding retriever to pull relevant passages from a corpus and hand them to the generator as ground truth. Here, the extraction call is the retriever. It has distilled the 8,000-word contract into roughly 35 structured observations. That becomes the generator's entire universe.
Three concrete effects:
- The model cannot hallucinate new clauses. It is physically impossible for the summary to reference a clause not in the structured input. Starving the model of the ability to invent facts is stronger hallucination prevention than any prompt instruction.
- Cost and latency drop. Roughly 2,000 input tokens instead of 15,000 — about 7x cheaper on input, 3x faster end-to-end.
- The model must synthesize, not transcribe. Handed raw legal text, LLMs quote it back. Handed structured observations, they have to rephrase. The output reads like analysis because the model was forced to do analysis.
In a multi-stage pipeline, the output of LLM call N becomes the structured input for LLM call N+1. Never pass the raw source material downstream if the earlier stage has already extracted what matters.
Real Example: NDA Summary Output#
Here is the executive summary for the Mutual NDA, produced by the second call:
EXECUTIVE SUMMARY: MUTUAL NON-DISCLOSURE AGREEMENT
This Mutual Non-Disclosure Agreement presents a medium overall risk profile (30.7/100) with generally balanced protections between the parties. The agreement contains standard NDA provisions with appropriate confidentiality obligations, reasonable survival periods, and clear IP ownership protections. Most clauses are low-risk and favor neither party disproportionately, indicating a fundamentally sound agreement structure.
However, two material concerns require attention before execution. First, the dispute resolution clause unilaterally designates Santa Clara County, California as the exclusive venue, creating significant litigation cost and inconvenience for the Texas-based party. This provision is one-sided and heavily favors Quantum Dynamics Corp. (the California-based counterparty). Second, the governing law provision similarly favors California law without negotiation, which may disadvantage the non-California party in legal interpretation and procedural matters.
A critical gap exists in the absence of any liability cap or limitation clause. This omission exposes both parties to potentially unlimited damages in breach scenarios, which is unusually risky for a confidentiality agreement and warrants immediate attention.
We recommend negotiating this agreement before signing, with priority focus on: (1) modifying the dispute resolution venue to a neutral location, (2) revising governing law to a mutually acceptable state, and (3) adding a reasonable liability cap to limit exposure.
Every specific fact — "Santa Clara County," "Texas-based party," "Quantum Dynamics Corp," "unlimited damages" — came from the structured input I passed in. I can point at the exact clause entry or finding that produced each claim. A reviewer with no legal training can audit the summary against the clause list on the same page.
That is only possible because of the grounding decision. The model is not summarizing the contract. It is rewriting the analysis of the contract as prose. The difference sounds subtle. It is the entire reason the output does not hallucinate.
Real Numbers#
For the three sample contracts:
| Stage | NDA | SaaS | Employment |
|---|---|---|---|
| Clause extraction (LLM call 1) | 8.2s | 14.1s | 17.8s |
| Risk scoring (Python) | <1ms | <1ms | <1ms |
| Findings generation (Python) | <1ms | <1ms | <1ms |
| Recommendations (Python) | <1ms | <1ms | <1ms |
| Executive summary (LLM call 2) | 4.5s | 6.8s | 8.1s |
| Total | 12.7s | 20.9s | 25.9s |
Scoring, findings, and recommendations together take under 2 milliseconds for any contract. The entire latency budget is LLM calls, and the summary call is about half the duration of the extraction call because it operates over roughly 2,000 tokens instead of 15,000.
Cost per analysis: approximately $0.005 to $0.010 total across both AI calls. Sub-penny per contract.
The gap between AI stages and Python stages is not 10x or 100x — it is roughly 10,000x. Every function you correctly keep in Python runs ten thousand times faster than the equivalent AI call. That is the scale of savings you leave on the table when you reach for AI by default.
What's Next#
In Blog 4: Streaming Progress with Server-Sent Events, we'll tackle the UX problem these long AI calls create — how to stream progress from a FastAPI endpoint back to the browser when the user is staring at a blank screen for 25 seconds.
This is post 3 of 5 in the Contract Analyzer Series. The full series covers architecture, clause extraction, risk scoring, streaming UX, and legal-tech frontend design for an AI-powered contract analyzer.
All code is open source: github.com/MinhQuanBuiSco/contract-analyzer