Deep Research Agent Series — Blog 1: Architecture & Vision#
You need to research a complex topic — say, "What are the latest advances in quantum computing and their commercial applications?" A single LLM call gives you a generic overview. But what if you could decompose that question into focused sub-queries, dispatch a swarm of AI researchers to investigate each one in parallel, critique the findings for quality, and synthesize everything into a comprehensive cited report — all in under 20 seconds?
That's exactly what we built. In this 6-part series, I'll walk you through the design and implementation of a production-grade Deep Research Agent deployed on AWS — from multi-agent orchestration to real-time streaming to infrastructure-as-code.
This first post covers the architecture and vision — the system design, tech stack decisions, research pipeline, and project structure that form the foundation for everything that follows.
The Deep Research Agent Series#
| Part | Title | Focus |
|---|---|---|
| 1 | Architecture & Vision (this post) | System design, tech stack, pipeline overview |
| 2 | Multi-Agent Orchestration | Strands SDK, parallel agents, critique loop |
| 3 | Smart Search & Source Intelligence | Tavily integration, credibility scoring, dedup |
| 4 | Real-Time Streaming with WebSocket | WebSocket architecture, CloudFront keepalive |
| 5 | Cloud-Native Infrastructure on AWS | 9 CDK stacks, VPC design, Fargate |
| 6 | Security & Production Hardening | Cognito auth, WAF, Bedrock Guardrails, CI/CD |
What We're Building#
A full-stack AI research platform that combines conversational chat with deep research capabilities.
Live Demo#
 The login page — Google OAuth or email/password via Amazon Cognito
The login page — Google OAuth or email/password via Amazon Cognito
 The main chat interface with suggestion cards, conversation sidebar, and editorial "Ink & Paper" design
The main chat interface with suggestion cards, conversation sidebar, and editorial "Ink & Paper" design
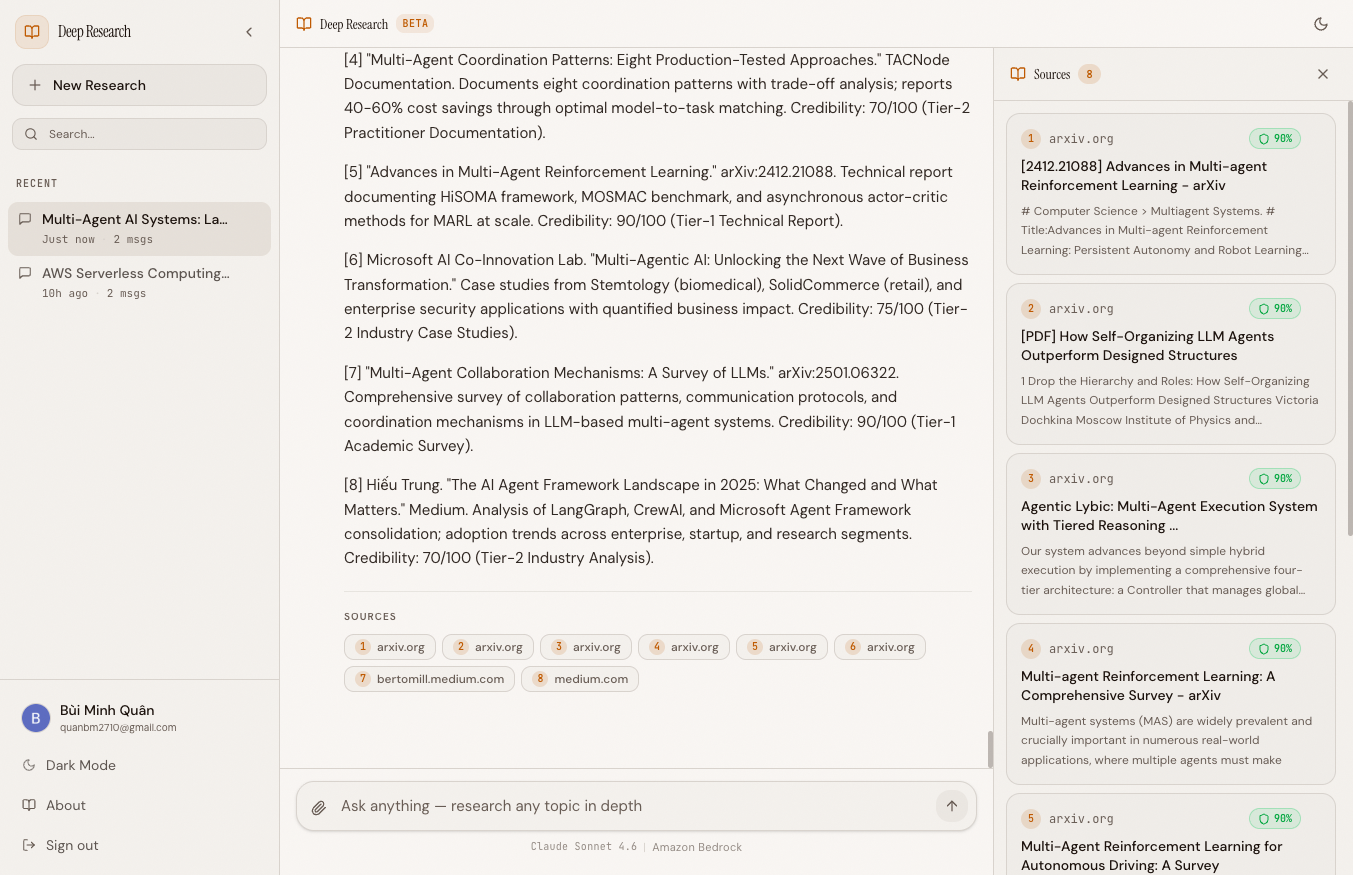 A completed research report with inline citations and source panel showing credibility scores
A completed research report with inline citations and source panel showing credibility scores
Features#
- 🔍 Conversational chat + deep research modes — simple questions get fast answers, complex ones trigger the full pipeline
- 🤖 Parallel multi-agent research pipeline — multiple AI researchers working simultaneously
- ⚡ Real-time streaming over WebSocket — watch the research happen live
- 🔐 Google OAuth via Amazon Cognito — managed authentication with social login
- 🏗️ 9 AWS CDK stacks — fully automated infrastructure-as-code
High-Level Architecture#
User → React 19 → WebSocket → FastAPI → Orchestrator Agent
↓
┌─────────┼─────────┐
↓ ↓ ↓
Researcher Researcher Researcher
(Tavily) (Tavily) (Tavily)
└─────────┼─────────┘
↓
Critique Agent
↓
Synthesize Report
↓
Stream to Client + Save
The user sends a question through a React 19 frontend. The WebSocket connection feeds it to a FastAPI backend, where an Orchestrator Agent decides whether to chat or research. If it's a research query, the orchestrator decomposes it into sub-queries, spawns parallel researcher agents, critiques the results, and synthesizes a final report — all while streaming progress updates back to the client.
Tech Stack Decisions#
Every technology choice was made deliberately. Here's the full stack and the reasoning behind each pick:
| Layer | Technology | Why |
|---|---|---|
| AI Model | Claude Haiku 4.5 via Bedrock | Fast, cost-effective for parallel agents |
| Agent SDK | Strands Agents SDK | Clean tool decorators, async support, Bedrock native |
| Backend | Python 3.12 + FastAPI | Async-first, WebSocket support |
| Frontend | React 19 + TypeScript + Vite | Modern, fast HMR |
| Search | Tavily API | Purpose-built for AI search |
| Auth | Amazon Cognito + Google OAuth | Managed auth with social login |
| Infrastructure | AWS CDK (Python) | Type-safe IaC |
| Database | DynamoDB (single-table) | Serverless, pay-per-request |
| Container | ECS Fargate | No server management |
A few decisions worth highlighting:
Why Strands over LangChain or CrewAI? Strands Agents SDK is AWS-native — it integrates directly with Amazon Bedrock without adapter layers. Its @tool decorator pattern is clean, and it supports asyncio.gather out of the box for parallel agent execution. No framework lock-in, no chain abstractions to fight against.
Why Claude Haiku 4.5? When you're running 4 agents in parallel, cost and latency matter more than maximum intelligence. Haiku 4.5 is fast enough to keep total research time under 20 seconds and cheap enough that parallel execution doesn't blow up your bill.
Why DynamoDB single-table? Chat history and research reports share access patterns (lookup by user + timestamp). A single-table design with composite keys avoids the overhead of managing multiple tables while keeping queries efficient.
The Research Pipeline#
The core of the system is a 6-step research pipeline that transforms a user question into a comprehensive cited report:
Step 1: Mode Detection#
Not every message needs a research pipeline. A simple "What's the capital of France?" should get a quick chat response. The system uses a heuristic to classify incoming messages:
def _should_research(message: str) -> bool: """Heuristic to decide if a message warrants deep research.""" research_keywords = [ "compare", "analyze", "research", "investigate", "explain in detail", "comprehensive", "deep dive", "survey", "state of", "landscape", "pros and cons", "advantages and disadvantages", "how does", "what are the latest", "current state", "trends", ] msg_lower = message.lower() if len(message) < 30: return False if any(kw in msg_lower for kw in research_keywords): return True if msg_lower.count("?") > 1 or msg_lower.count(" and ") > 1: return True return False
The logic is intentionally simple: short messages are always chat, keyword matches trigger research, and multiple questions or conjunctions suggest complexity. This avoids the latency of an LLM classification call — the heuristic runs in microseconds.
Step 2: Query Decomposition#
The orchestrator breaks the original question into 4 focused sub-queries. For example:
Input: "Compare LangChain, CrewAI, and Strands for building production AI agents"
Sub-queries:
- "LangChain framework features, architecture, and production readiness 2026"
- "CrewAI multi-agent capabilities, strengths, and limitations"
- "Strands Agents SDK features, AWS integration, and developer experience"
- "Comparison of AI agent frameworks for production deployment"
Step 3: Parallel Research#
Each sub-query is assigned to an independent researcher agent. All four run simultaneously via asyncio.gather, each performing web searches through the Tavily API and extracting relevant information.
Step 4: Consolidation#
Raw results from all researchers are consolidated — duplicate sources are removed, and sources are ranked by credibility (official docs > academic papers > news > blogs).
Step 5: Critique#
A dedicated critique agent reviews the consolidated findings and assigns a verdict:
- PASS — findings are comprehensive and well-sourced
- REFINE — gaps identified, specific sub-queries re-run
- FAIL — fundamental issues, full re-research triggered
Step 6: Synthesis#
The final step produces a comprehensive report with inline citations ([1], [2], [3]), structured sections, and a bibliography. The report is streamed to the client in real-time and persisted to S3 + DynamoDB.
Why Parallel Agents?#
This is the single most impactful architectural decision in the system. Here's the math:
Sequential execution:
- 4 sub-queries × ~15 seconds each = ~60 seconds total
- User stares at a loading spinner for a full minute
Parallel execution with asyncio.gather:
- 4 sub-queries running simultaneously = ~16 seconds total (bounded by the slowest agent)
- Nearly 4x speedup with zero additional cost
The key insight is that each researcher agent is completely independent — different sub-query, different Tavily searches, different Bedrock invocations. There's no shared state between them, which makes parallelism trivial:
results = await asyncio.gather( research_sub_query(agent_1, sub_query_1), research_sub_query(agent_2, sub_query_2), research_sub_query(agent_3, sub_query_3), research_sub_query(agent_4, sub_query_4), )
Each agent gets its own Strands SDK instance, its own Bedrock session, and its own Tavily API calls. No locks, no coordination, no bottlenecks.
For user experience, the difference between 16 seconds and 60 seconds is the difference between "this is useful" and "I'll just Google it myself."
Project Structure#
The codebase is organized by concern, with clear boundaries between the backend pipeline, frontend UI, and infrastructure:
deep_research_agent/
├── backend/
│ ├── app.py # FastAPI + WebSocket entry
│ ├── config.py # Pydantic Settings
│ ├── worker.py # SQS async worker
│ ├── agents/
│ │ ├── orchestrator.py # Research pipeline
│ │ ├── researcher.py # Sub-agent factory
│ │ ├── critique.py # Quality reviewer
│ │ └── prompts.py # All system prompts
│ ├── tools/
│ │ ├── tavily_search.py # Web search + circuit breaker
│ │ ├── credibility_scorer.py # Source credibility
│ │ ├── plan_research.py # Query decomposition
│ │ └── save_report.py # S3 + DynamoDB persistence
│ ├── middleware/
│ │ └── auth.py # Cognito JWT verification
│ └── services/
│ ├── chat_history.py # DynamoDB conversation store
│ └── research_queue.py # SQS job management
├── frontend/ # React 19 + TypeScript
├── infra/ # AWS CDK (9 stacks)
└── docker-compose.yml # Local dev
A few structural decisions worth noting:
Prompts are centralized in prompts.py — not scattered across agent files. This makes prompt iteration fast and keeps agent logic focused on orchestration.
Tools are self-contained with their own error handling and circuit breakers. The Tavily search tool, for example, includes retry logic and graceful degradation if the API is down.
Infrastructure is colocated in the same repo. The 9 CDK stacks live alongside the application code, ensuring that infrastructure changes are reviewed and deployed together with application changes.
What's Next#
In Blog 2: Multi-Agent Orchestration, we'll dive into the implementation details — how Strands Agents SDK creates orchestrator, researcher, and critique agents, how asyncio.gather coordinates parallel execution, and how the critique loop decides whether findings are good enough or need refinement.
All code is open source: github.com/MinhQuanBuiSco/deep-research-agent