Clinical Research Series — Blog 1: Architecture & Domain Analysis#
I've built AI agents for tech research. Here's what changed when I adapted it for medicine — where hallucinations can kill.
My Deep Research Agent decomposes questions, dispatches parallel researchers, critiques findings, and synthesizes cited reports. My Context Engine cuts token usage by 34%. My Agent Observability layer traces every span, evaluates quality, and tracks cost. All three work well for technology research — where the worst case is a wrong API recommendation.
Then I tried to use it for a medical question: "What is the current evidence for GLP-1 receptor agonists in treating Type 2 Diabetes with comorbid cardiovascular disease?"
The agent confidently stated a specific dosage. It cited a study that doesn't exist. It presented a Phase II trial result as established clinical practice. None of these would matter for a question about React Server Components. For a question about diabetes treatment, they could genuinely harm someone.
This series documents what I built to fix that — a clinical research agent with PubMed integration, evidence grading, hallucination detection, and safety guardrails that make sure every medical claim has a citation.
The Clinical Research Series#
| Part | Title | Focus |
|---|---|---|
| 1 | Architecture & Domain Analysis (this post) | System design, evidence hierarchy, medical APIs |
| 2 | PubMed & ClinicalTrials.gov Integration | E-utilities, v2 API, OpenFDA, circuit breakers |
| 3 | Safety & Hallucination Prevention | Uncited claim detection, credibility scoring |
| 4 | Evidence Grading & Citation Quality | Level I-V, PMID/NCT citations, journal tiers |
| 5 | Medical Frontend & Production Readiness | Teal theme, EvidencePanel, SafetyAlert |
The SA-Pro Portfolio: Build -> Optimize -> Monitor -> Apply to Domain#
This is the fourth project in a portfolio arc that follows a deliberate progression:
| Series | Project | Question Answered |
|---|---|---|
| Deep Research Agent | Build | How do you build a multi-agent research pipeline? |
| Context Engine | Optimize | How do you reduce token waste by 34%? |
| Agent Observability | Monitor | How do you see what your agent is actually doing? |
| Clinical Research Agent (this series) | Apply to Domain | How do you adapt AI agents for safety-critical domains? |
Each project builds on the previous codebase. The Clinical Research Agent reuses the Context Engine's token budgeting and deduplication, the Observability layer's tracing, and the Deep Research Agent's parallel research pattern. But it adds an entirely new dimension: domain-specific safety.
The first three projects answer engineering questions. This one answers a domain question: can you trust an AI agent enough to use it for medical research?
Why Healthcare Is Different#
Building AI for healthcare isn't just "the same thing with medical data." Three properties make it fundamentally different from tech research:
1. Regulated and Liability-Sensitive#
A tech research agent that says "React 19 supports server components" when it actually doesn't — that wastes 30 minutes of a developer's time. A medical research agent that says "metformin is safe for patients with severe renal impairment" when it isn't — that could contribute to a clinical decision that harms a patient.
Every response must include a disclaimer. Every claim must have a citation. Every dose mention must be flagged.
2. Evidence Hierarchy#
Not all studies are equal. A meta-analysis of 50 randomized controlled trials is stronger evidence than a single case report. Medical professionals think in terms of evidence levels — and an AI agent that doesn't distinguish between a Cochrane review and an editorial letter is worse than useless; it's misleading.
3. Source Credibility Varies#
A result from the New England Journal of Medicine is not the same as a result from a health blog. A registered clinical trial on ClinicalTrials.gov is not the same as a preprint on medRxiv. The agent needs to score every source and communicate that score to the user.
Architecture Overview#
The clinical research pipeline follows the same decompose-research-critique-synthesize pattern as the Deep Research Agent, but wraps every stage with medical-specific validation:
User Query
│
▼
┌─────────────────────────────────────────────────────────┐
│ CONTEXT ENGINE (Pre-processing) │
│ Complexity classification → Token budget → Sub-queries │
└────────────────────────┬────────────────────────────────┘
│
┌───────────────┼───────────────┐
▼ ▼ ▼
┌─────────────┐ ┌──────────────┐ ┌──────────────┐
│ PubMed │ │ ClinicalTrials│ │ OpenFDA │
│ E-utilities│ │ .gov v2 │ │ Drug Events │
│ (36M+ docs)│ │ (500K+ trials)│ │ (adverse) │
└──────┬──────┘ └──────┬───────┘ └──────┬───────┘
│ │ │
▼ ▼ ▼
┌──────────────────────────────────────────────────────┐
│ EVIDENCE GRADING (Level I-V) │
│ Meta-analysis → RCT → Cohort → Case report → Opinion│
└────────────────────────┬─────────────────────────────┘
│
▼
┌──────────────────────────────────────────────────────┐
│ CREDIBILITY SCORING │
│ NEJM=98 PubMed=90 Trial=92 Preprint=55 Blog=40 │
└────────────────────────┬─────────────────────────────┘
│
▼
┌──────────────────────────────────────────────────────┐
│ CRITIQUE AGENT │
│ Reviews findings for accuracy and completeness │
└────────────────────────┬─────────────────────────────┘
│
▼
┌──────────────────────────────────────────────────────┐
│ SYNTHESIS │
│ Markdown report with inline [1] PMID citations │
└────────────────────────┬─────────────────────────────┘
│
▼
┌──────────────────────────────────────────────────────┐
│ SAFETY LAYER │
│ Hallucination detection → Safety check → Disclaimer │
└────────────────────────┬─────────────────────────────┘
│
▼
Final Report
(with evidence badges, safety
alerts, and medical disclaimer)
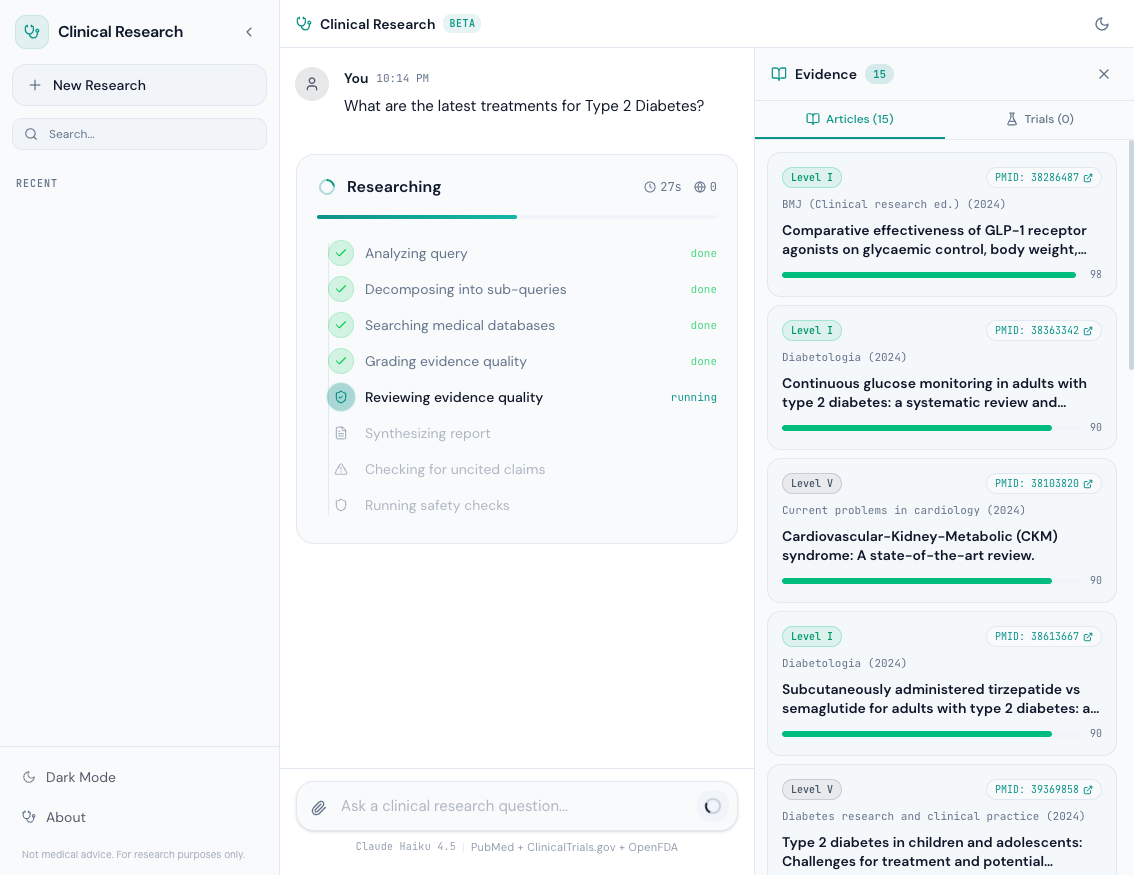
Every stage emits structured events to the frontend via WebSocket, so the user sees real-time progress: "Searching medical databases...", "Grading evidence quality...", "Checking for uncited claims...".
Tech Stack#
| Component | Technology | Purpose |
|---|---|---|
| AI Model | Claude Haiku 4.5 via Amazon Bedrock | Fast inference for multi-agent pipeline |
| Agent Framework | Strands Agents SDK | Tool-use orchestration with @tool decorator |
| Medical Literature | PubMed E-utilities API | 36M+ peer-reviewed biomedical articles |
| Clinical Trials | ClinicalTrials.gov API v2 | 500K+ registered clinical trials |
| Drug Safety | OpenFDA API | Adverse event reports, drug reactions |
| Web Supplement | Tavily API | Supplementary web search |
| Backend | Python 3.12 + FastAPI | WebSocket streaming, async research pipeline |
| Frontend | React 19 + TypeScript + Vite + Tailwind v4 | Medical teal theme, evidence panels |
| Config | Pydantic Settings | Type-safe environment configuration |
| HTTP Client | httpx | Async HTTP with timeouts for all medical APIs |
The model choice is deliberate. Claude Haiku 4.5 via Bedrock gives us fast inference at low cost — important when a single research query dispatches 3-4 parallel sub-queries, each making multiple tool calls. The Strands SDK's @tool decorator makes it trivial to expose PubMed, ClinicalTrials, and OpenFDA as agent tools.
Configuration: Safety-First Defaults#
The configuration reflects the safety-critical nature of the domain. Here's the full settings class:
class Settings(BaseSettings): """Application settings loaded from environment.""" # AWS (Bedrock only) aws_region: str = "us-east-1" bedrock_model_id: str = "us.anthropic.claude-haiku-4-5-20251001-v1:0" bedrock_guardrail_id: str = "" bedrock_guardrail_version: str = "DRAFT" # Medical APIs pubmed_api_key: str = "" # Optional: increases rate limit from 3 to 10 req/s tavily_api_key: str = "" # Context Engine token_budget_default: int = 300_000 # Higher for medical content enable_context_xray: bool = True # Clinical Safety require_citations: bool = True max_pubmed_results: int = 10 max_trials_results: int = 10 max_openfda_results: int = 5 # App log_level: str = "INFO" environment: str = "dev" cors_origins: list[str] = ["http://localhost:5173"] model_config = {"env_prefix": "", "case_sensitive": False}
A few things worth noting:
token_budget_default: 300_000— higher than the 200K default in the Context Engine. Medical content is denser: abstracts contain statistics, dosages, and study design details that compress poorly. The Context Engine's complexity classifier adapts the actual budget per query, but the ceiling is higher.require_citations: bool = True— this flag gates the hallucination detector. In tech research, uncited claims are fine. In medical research, they're dangerous.max_pubmed_results: 10— we cap at 10 articles per sub-query to keep token usage reasonable while ensuring enough evidence for grading.bedrock_guardrail_id— Bedrock Guardrails can be configured to block harmful medical advice at the model level. This is a second safety net beyond our application-level hallucination detector.
The Evidence Hierarchy: Level I through V#
Evidence-based medicine uses a well-established hierarchy. Our system grades every PubMed article against it:
class EvidenceLevel(Enum): LEVEL_I = "I" # Systematic reviews, meta-analyses LEVEL_II = "II" # Randomized controlled trials (RCTs) LEVEL_III = "III" # Non-randomized controlled studies LEVEL_IV = "IV" # Case series, case reports LEVEL_V = "V" # Expert opinion, editorials, reviews
| Level | Study Design | Example | Color Badge |
|---|---|---|---|
| I | Systematic review or meta-analysis | Cochrane review of 50 RCTs | Emerald |
| II | Randomized controlled trial (RCT) | Phase III multicenter trial | Blue |
| III | Non-randomized controlled study | Cohort study, observational study | Amber |
| IV | Case series or case report | Single patient case report | Orange |
| V | Expert opinion or editorial | Journal editorial, practice guideline | Gray |
The grading uses PubMed's publication type metadata — every article in PubMed is tagged with types like "Meta-Analysis", "Randomized Controlled Trial", or "Case Reports". We map these directly:
_LEVEL_I_TYPES = { "meta-analysis", "systematic review", "systematic reviews", "meta analysis", "cochrane review", "umbrella review", } _LEVEL_II_TYPES = { "randomized controlled trial", "rct", "clinical trial, phase iii", "clinical trial, phase iv", "multicenter study", "pragmatic clinical trial", }
When the publication type metadata is missing or ambiguous, the grader falls back to keyword detection in the title and abstract — looking for terms like "meta-analysis", "randomized", "cohort", or "case report". This two-pass approach catches articles that PubMed hasn't fully indexed yet.
The frontend renders these as colored badges next to each article in the evidence panel, giving the user an immediate visual signal of evidence strength.
The Research Pipeline: 10 Steps#
The orchestrator runs a 10-step pipeline for every research query. Here's the sequence as implemented in orchestrator.py:
- Classify complexity — the Context Engine determines how many sub-queries to generate and what token budget to allocate
- Decompose into sub-queries — a planner agent breaks the question into focused, non-overlapping search queries
- Parallel research — each sub-query dispatches a researcher agent that calls PubMed and ClinicalTrials.gov via
asyncio.gather - Evidence grading — every article gets a Level I-V grade based on publication type
- Credibility scoring — every source gets a 0-100 credibility score based on journal tier and domain
- Deduplication — articles are deduped by PMID, trials by NCT ID, findings by semantic similarity
- Critique — a separate agent reviews findings for accuracy, completeness, and gaps
- Synthesis — a report writer produces markdown with inline
[1],[2]citations referencing PMIDs - Hallucination detection — regex-based scanner flags uncited medical claims with severity levels
- Safety check — verifies disclaimer presence, flags dose recommendations, emits safety events
Steps 4 and 5 happen inline during Step 3 — as each PubMed result comes back, the source-capturing tool wrapper grades and scores it immediately. This is a key design choice: we don't wait until all research is complete to assess evidence quality. The frontend can show evidence badges as they arrive.
Screenshots#
The landing page uses a medical teal theme to visually distinguish it from the tech research agent:
During research, the progress panel shows each pipeline stage in real time:
AWS Profile Setup#
Like the other projects in this portfolio, the Clinical Research Agent uses Amazon Bedrock for model inference. You'll need an AWS profile with Bedrock access:
# Set your AWS profile and optional API keys AWS_PROFILE=your-profile \ TAVILY_API_KEY=tvly-xxx \ uv run uvicorn app:app --reload --port 8000
No other AWS services are used. No DynamoDB, no S3, no Lambda. The only cloud dependency is Bedrock for LLM inference. PubMed, ClinicalTrials.gov, and OpenFDA are all free public APIs — no API key required for PubMed (though one increases the rate limit from 3 to 10 requests per second).
What's Next#
The architecture is the map. In Blog 2: PubMed & ClinicalTrials.gov Integration, we'll build the tools that actually search 36 million peer-reviewed articles and 500,000 clinical trials — with XML parsing, structured data extraction, and circuit breakers that gracefully handle API failures without crashing the pipeline.
All code is open source: github.com/MinhQuanBuiSco/clinical-research-agent