Aurora Market Series — Blog 1: Architecture & The Agentic Commerce Bet#
A chat-driven shopping app is mostly the app you already have, with a chat box bolted on. The user asks a question, the model answers, the user clicks a product, the user checks out. Conversation is decorative. The transaction still flows through the same screens.
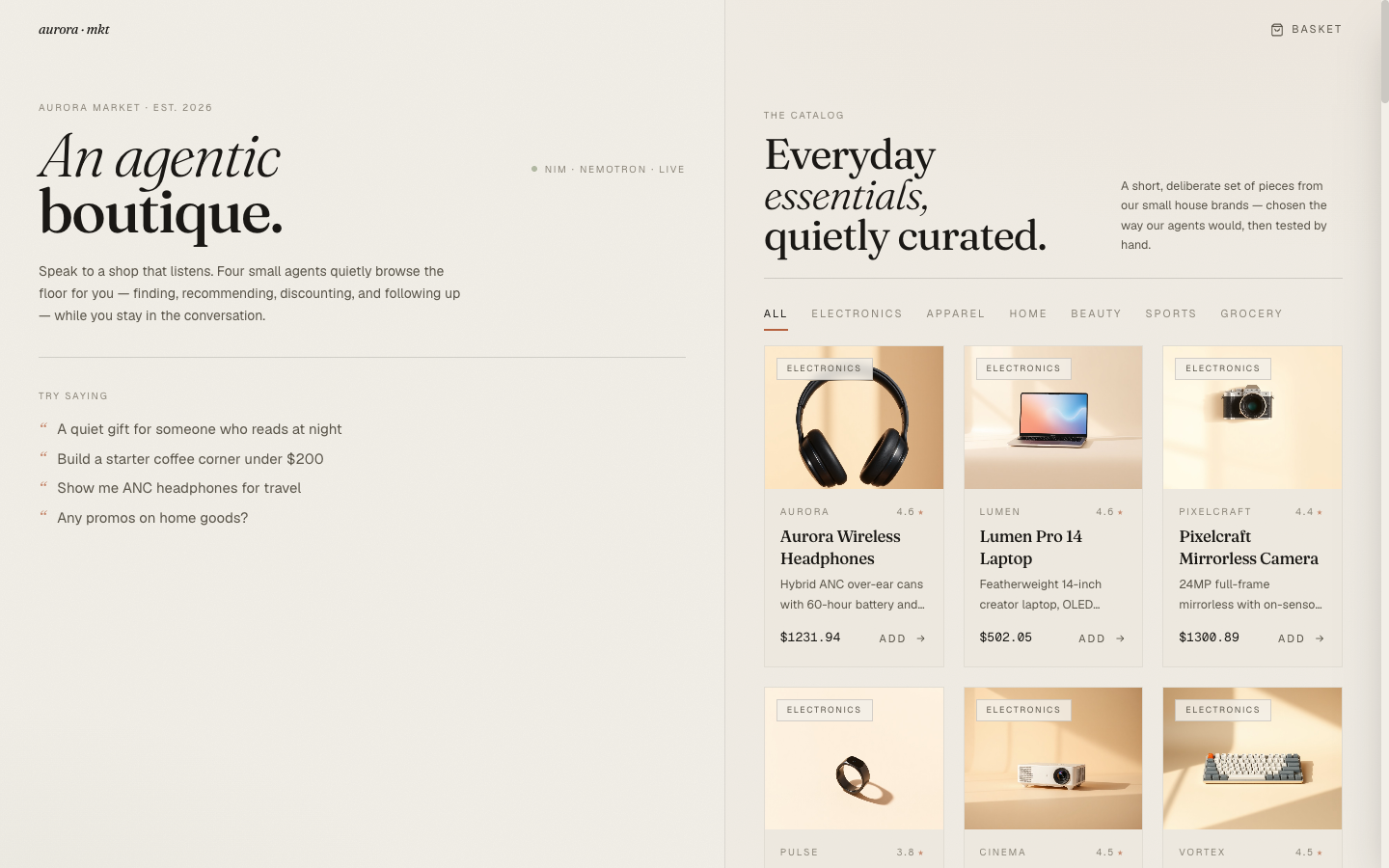
Agentic commerce is the other direction. Small specialists quietly browse the floor on your behalf — search for what you said, recommend what fits the cart, offer a discount if there's one to offer, follow up after the purchase — and you stay in the conversation the whole time. The agents are the storefront, not an overlay on top of one.
I wanted to know whether that distinction held up in code, so I built a working demo of it. Aurora Market is a one-screen agentic storefront powered entirely by NVIDIA's hosted NIM API — no GPUs, no self-hosted models — with four specialist agents, an orchestrator, semantic product search, an ACP-style mock checkout, and a frontend you'd want to actually use. This series documents the architecture, the four agents and their shared tool-calling loop, the router that broke and how I fixed it, the streaming UX that makes the system feel alive, the catalog images I ended up generating with FLUX, and the editorial design that kept it from looking like another AI chat clone.
Reference: This project follows the architectural patterns laid out in NVIDIA's Retail-Agentic-Commerce blueprint — four specialist agents, ACP-style delegated checkout, NIM as the inference layer. The implementation is independent and runs entirely against the hosted NIM API at build.nvidia.com, so the GPU requirement of the upstream blueprint goes to zero. If you want the full multi-service blueprint with delegated payments and the broader NAT agent integration, start there.
The Aurora Market Series#
| Part | Title | Focus |
|---|---|---|
| 1 | Architecture & The Agentic Commerce Bet (this post) | Why four specialists instead of one mega-agent, NIM as the inference layer, ACP-style mock checkout, tech stack |
| 2 | Four Specialists, One Tool-Calling Loop | The base agent loop, per-agent system prompts, cart context as a tool |
| 3 | The Router That Wouldn't Route + the Nemotron <think> Trap | LLM router + keyword backstop, reasoning-mode reply truncation, the chat_template_kwargs fix |
| 4 | Realtime: SSE, Live Agent Chips, and Token Streams | SSE-over-POST events, in-flight pills, the React reducer pattern for streaming state |
| 5 | Generating the Catalog: Picsum → LoremFlickr → FLUX.1-schnell | Three iterations of thumbnail accuracy, the prompt template, the variant-share-base-photo trick |
| 6 | Editorial Aesthetic for an AI Storefront | Why default chat aesthetics fail commerce, Fraunces + Geist, clay + sage, the agent chip as a transparency device |
The SA-Pro Portfolio: Build → Optimize → Monitor → Apply to Domain × 3#
This is the third domain-application in the same portfolio arc. The pattern: build a generic system, optimize it, instrument it, then port the pattern into a domain with its own constraints.
| Series | Project | Question Answered |
|---|---|---|
| Deep Research Agent | Build | How do you build a multi-agent research pipeline? |
| Context Engine | Optimize | How do you reduce token waste by 34%? |
| Agent Observability | Monitor | How do you see what your agent is actually doing? |
| Clinical Research Agent | Healthcare Domain | How do you adapt AI for safety-critical medicine? |
| Contract Analyzer | Legal Domain | How do you apply AI to document-heavy business processes? |
| Aurora Market (this series) | Commerce Domain | How do you turn a chat agent into a storefront? |
What "Agentic Commerce" Actually Means#
The phrase is doing a lot of work right now. NVIDIA, Stripe, OpenAI, and Shopify each use it for a slightly different thing. The common thread is the one I care about: shopping where the buyer's intent is expressed in natural language and a set of small autonomous components do the work — discovery, recommendation, pricing, checkout, support — without the buyer steering through a multi-page funnel.
What that looks like in practice depends on which surface you put it on. I picked the simplest possible one: a storefront with a chat panel on the left and a browsable catalog on the right. A shopper can ask, or they can browse. Either way, the same four agents are running underneath. The chat is not a replacement for the catalog; it's a parallel interface to the same data.
This matters because most "AI shopping" products today are either (a) a chatbot that links out to PDP pages or (b) a search bar with a thesaurus. Neither one is agentic. The bot just talks; the search bar just looks up. There is no specialist actually doing anything. The bet I wanted to test was whether splitting the work into four small specialists with a routing layer would feel meaningfully different from a single big chat agent doing all four jobs in one prompt.
It does. The rest of this post is the architecture that makes that difference cheap to express.
Why Four Specialists Instead of One Mega-Agent#
The default move when you reach for an AI agent is to build one. Give it a fat system prompt that says "you are a helpful shopping assistant who can search the catalog, recommend products, apply promos, and handle order questions," wire up four tools, let it tool-call its way through whatever the user asked. This works for a demo. It does not survive contact with a real catalog.
The first thing that breaks is the persona collision. A search agent wants to be exhaustive and literal — it should list every relevant hit and let you narrow down. A recommender wants to be selective and opinionated — three picks with rationale, not twelve. A promotions agent is a rules engine in a trench coat — it should look at the cart, compare against eligibility, and answer in one sentence. A post-purchase agent is a support voice — calm, empathetic, concrete. Trying to be all four at once produces the bland averaged voice that makes shopping chatbots feel like they were written by a compliance officer.
The second thing that breaks is tool sprawl. If one agent has every tool, the model has to decide between them at every turn. The decision quality drops as the tool count grows. Worse, the tools start sharing context — the cart-context tool is needed by both the recommender and the promotion engine, but a search-only turn shouldn't load it. Splitting agents lets each one carry the minimum tool surface it actually needs.
The third is routing as a first-class concern. When a user says "what else should I get to go with these and any promo I can stack?", they're asking for two things. A mega-agent has to detect that and run two cognitive passes inside a single tool loop, which it'll botch about a third of the time. A router that explicitly chooses ["recommend", "promotion"] and dispatches to both specialists is more reliable and produces better composition, because each specialist can run a focused tool-calling loop without contending with the other.
So I built four specialists — search, recommend, promotion, post_purchase — plus an orchestrator with two jobs: a router LLM that picks the agents for this turn, and a composer LLM that fuses their outputs into one warm reply for the shopper. The next post covers the agents themselves; the one after that covers the router (and the bug that almost killed it).
NIM as the Inference Layer (Zero GPU)#
The original NVIDIA Retail Agentic Commerce blueprint can be self-hosted on 2× A100s or 2× H100s. I have neither. What I do have is an NVIDIA developer key and the hosted NIM API at build.nvidia.com, which exposes both an LLM endpoint (Nemotron Nano 9B v2) and an embedding endpoint (NV-EmbedQA-E5-v5) over an OpenAI-compatible interface. The whole project runs against those two endpoints from my laptop.
Two consequences fall out of that.
First, the client surface area is tiny. NIM speaks OpenAI's chat completions API for the LLM, so I instantiate the standard openai.OpenAI client pointed at https://integrate.api.nvidia.com/v1 and reuse it for chat, tool calls, and streaming. The embedding endpoint is a plain JSON POST. The total NIM client module is under eighty lines including streaming, retries, and a defensive <think>-tag stripper I'll get to in Blog 3.
from openai import OpenAI client = OpenAI(api_key=NVIDIA_API_KEY, base_url="https://integrate.api.nvidia.com/v1") resp = client.chat.completions.create( model="nvidia/nvidia-nemotron-nano-9b-v2", messages=[...], tools=[...], tool_choice="auto", extra_body={"chat_template_kwargs": {"thinking": False}}, )
Second, model selection becomes a configuration concern, not an architectural one. Nemotron Nano 9B is small enough to be fast and cheap, capable enough for tool calling, and runs at no infrastructure cost to me. If I want to swap in a Llama 4 or a Qwen 2.5 deployment later, I change one env var. None of the agent code, the orchestrator, or the frontend cares. The OpenAI-compatible interface is doing a lot of unglamorous work here.
The embedding endpoint is just as plain. NV-EmbedQA-E5-v5 returns 1024-dim float vectors. I push them straight into Milvus with no transformation. The whole "vectorize the catalog" step at seed time is about thirty lines.
ACP-Style Mock Checkout#
I wanted the checkout flow to follow the shape of the Agentic Commerce Protocol that's emerging from the NVIDIA/Stripe/OpenAI side of the industry, even though this is a demo. ACP separates the session (the buyer's intent and cart) from the payment (the issuer-vault-protected tap), and routes payment through a delegated PSP so the merchant never touches raw card data.
In Aurora Market, that translates to:
POST /sessions -> { id: "cs_..." } # open a checkout session
POST /sessions/{id}/items -> add a product (or adjust qty)
POST /sessions/{id}/promo -> apply a promotion code
POST /sessions/{id}/pay -> mock PSP authorizes, returns Order
The PSP is a single file (app/psp.py) that returns a vt_<sha-prefix> vault token on every approved request and rejects any card whose number ends in 0002. The order record stores the vault token, never the card, and the snapshot of items at the moment of payment.
The point of this isn't to demonstrate a real payment integration — it's to make the agent surface coherent. The post_purchase agent, when a shopper later asks "where's my order," can look up an Order by session id, return tracking info, and reference the vault token if it ever needs to refund. That's only possible because the session and the order are real persistent objects, not stubs the chat agent invented on the fly. Even a mock checkout pays for itself the moment you want the post-purchase agent to behave.
Architecture Overview#
The end-to-end picture is small enough to fit in one diagram. Two LLM calls per turn (router + composer), some number of specialist agent calls in between (one per chosen agent, each with its own tool-calling loop), and a Milvus search whenever an agent decides to look at the catalog.
User message
│
▼
┌───────────────────────┐
│ /chat/stream (SSE) │ ──────────► Browser (event-stream)
└──────────┬────────────┘
│
▼
┌──────────────────────┐
│ Router LLM │ event: route {agents: [...]}
│ (Nemotron, JSON) │
└──────────┬───────────┘
│ pick 1–3 specialists
┌──────────┴──────────────────────────────┐
▼ ▼ ▼ ▼
search recommend promotion post_purchase
agent agent agent agent
│ │ │ │
│ tool │ tool │ tool │ tool
│ calls │ calls │ calls │ calls
▼ ▼ ▼ ▼
Milvus + Milvus + SQLite SQLite
SQLite SQLite (promos) (orders)
+ cart ctx + cart ctx
│ │ │ │
└──────────┬───┴───────┬──────┴─────────────┘
│ │ events: agent_start / agent_done / products / promo
▼ ▼
┌────────────────────────┐
│ Composer LLM (stream) │ events: composer_start → token → token → done
│ Fuses agent outputs │
└────────────────────────┘
The pipeline is strictly forward. No specialist talks to another specialist. There is no shared scratchpad. The only coordination is the orchestrator collecting outputs and the composer fusing them. That's the whole point of the design: each specialist is a leaf, the orchestrator is a tree of two levels, and the wire shape is SSE events the frontend can render as they happen. Blog 4 covers the SSE side in detail.
Tech Stack#
| Component | Technology | Purpose |
|---|---|---|
| LLM | Nemotron Nano 9B v2 via NVIDIA NIM | Router, all specialist agents, composer |
| Embeddings | NV-EmbedQA-E5-v5 via NVIDIA NIM | Product catalog vectors (1024-dim) |
| Image generation | FLUX.1-schnell via NVIDIA NIM | One product photo per base item at seed time |
| Backend | Python 3.12 + FastAPI + uv | Async routes, StreamingResponse for SSE |
| Vector store | Milvus 2.4 (standalone) | Semantic search over the product catalog |
| Relational store | SQLite + SQLAlchemy 2.0 | Products, promotions, sessions, orders |
| Mock PSP | Single Python file | ACP-style vault-token payment |
| Frontend | React 19 + Vite + TypeScript | Chat-driven storefront |
| Styling | Tailwind CSS v3 + Fraunces + Geist | Editorial boutique aesthetic |
| Infra | Docker Compose | api, milvus + etcd + minio, frontend |
What's deliberately missing: no LangChain, no LangGraph, no Redis, no message queue, no separate websocket server, no auth layer, no payment vendor. The agent loop is plain Python because the tool-calling pattern is forty lines and I'd rather own them than depend on a framework that's a moving target. Blog 2 has the loop.
The whole repo is around 2,500 lines split roughly evenly between the FastAPI backend and the React frontend. The catalog itself (39 base products, six categories) is generated synthetically at seed time so the project is reproducible without a bundled dataset.
What's Next#
This post was the bet and the shape. The rest of the series digs into the parts that took the most iteration:
- Blog 2 — the four agents and their shared
run_agent()loop. How each one carries different tools and different prompts, why the cart context is a tool (not a system message), and why I didn't reach for a multi-agent framework. - Blog 3 — the router that wouldn't route. The Nemotron Nano
<think>reasoning-mode trap that produced 23-character reply fragments. Thechat_template_kwargs: {thinking: false}fix and a keyword-route backstop for when the model JSON drifts. - Blog 4 — making the system feel alive. Server-Sent Events over POST, the seven event types the orchestrator emits, the React reducer that turns them into in-flight pills, an expandable AgentChip, and a token-by-token reply.
- Blog 5 — getting the catalog photos right. Three iterations: Picsum (random landscapes), LoremFlickr (keyword-fuzzy Flickr photos), and finally FLUX.1-schnell with a fixed prompt template. The variant-share-base-photo cache trick.
- Blog 6 — the editorial frontend. Why "AI chat" defaults are bad for commerce, the Fraunces + Geist + clay-and-sage palette, the chat-as-storefront layout, and the agent chip as a transparency device the user can open.
All six posts are live now. The repo is at github.com/MinhQuanBuiSco/retail-agentic-commerce.