Aurora Market Series — Blog 2: Four Specialists, One Tool-Calling Loop#
Blog 1 made the case for splitting the agent layer into four small specialists instead of one big one. This post is how that split survives contact with code: a single forty-line tool-calling loop, four agents built on top of it that share nothing except the loop, and a cart-context tool that quietly makes the recommender and the promotion engine work without spending a single token on cart contents that aren't needed.
I want to make one thing explicit upfront, because the multi-agent framework space is loud right now. There is no agent-to-agent communication in Aurora Market. No supervisor, no message passing, no blackboard. The orchestrator picks which agents to run, each agent runs its own tool-calling loop against the same NIM endpoint, and a composer fuses their text outputs at the end. That's it. The "multi-agent" pattern people are sold is mostly framework — and most of what the framework does is wire up things you don't need.
The Aurora Market Series#
| Part | Title | Focus |
|---|---|---|
| 1 | Architecture & The Agentic Commerce Bet | Four specialists, NIM as inference, ACP-style checkout |
| 2 | Four Specialists, One Tool-Calling Loop (this post) | The base loop, per-agent prompts, cart context as a tool |
| 3 | The Router That Wouldn't Route + the Nemotron <think> Trap | LLM router + keyword backstop, reasoning-mode reply truncation |
| 4 | Realtime: SSE, Live Agent Chips, and Token Streams | SSE-over-POST events, in-flight pills, React reducer pattern |
| 5 | Generating the Catalog: Picsum → LoremFlickr → FLUX.1-schnell | Three iterations of thumbnail accuracy |
| 6 | Editorial Aesthetic for an AI Storefront | Fraunces + Geist, clay + sage, agent chips as transparency |
The Loop#
The whole shared loop is in app/agents/base.py. It is a generic OpenAI-style tool-calling loop with one Aurora-specific affordance: every tool call's args and a truncated result preview are accumulated into call_log so the orchestrator can ship them down to the frontend for the expandable AgentChip in Blog 4. Apart from that it's textbook.
def run_agent( system: str, user_message: str, tools: list[Tool], history: list[dict[str, str]] | None = None, max_iters: int = 4, temperature: float = 0.2, ) -> AgentResult: messages = [{"role": "system", "content": system}] if history: messages.extend(history) messages.append({"role": "user", "content": user_message}) tool_map = {t.name: t for t in tools} tool_specs = [t.to_openai() for t in tools] if tools else None call_log, payloads = [], {} for _ in range(max_iters): resp = chat_completion(messages, tools=tool_specs, temperature=temperature) msg = resp.choices[0].message if not getattr(msg, "tool_calls", None): return AgentResult(text=(msg.content or "").strip(), tool_calls=call_log, raw_payload=payloads) messages.append({"role": "assistant", "content": msg.content or "", "tool_calls": [...]}) for tc in msg.tool_calls: name = tc.function.name args = json.loads(tc.function.arguments or "{}") tool = tool_map.get(name) result = tool.handler(**args) if tool else {"error": f"unknown tool {name}"} call_log.append({"name": name, "args": args, "result_preview": _preview(result)}) payloads[name] = result messages.append({"role": "tool", "tool_call_id": tc.id, "name": name, "content": json.dumps(result, default=str)}) # Out of iterations — ask for a final answer messages.append({"role": "user", "content": "Summarize your answer now."}) resp = chat_completion(messages, temperature=temperature) return AgentResult(text=(resp.choices[0].message.content or "").strip(), tool_calls=call_log, raw_payload=payloads)
Things worth pointing out:
max_iters=4is enough for every agent here because the longest reasonable chain is "look up cart, look up similar products, compose answer" — three tool calls. Four gives one cushion turn.- The forcing turn at the end ("Summarize your answer now") is what stops a runaway tool-call loop from returning an empty assistant message. If we hit the iteration cap, we ask for one final non-tool response and ship that.
payloadsandcall_logseparate concerns.payloadsis the raw tool output, indexed by tool name, which the agent code can read out after the loop ("didsearch_catalogactually run? give me its hits").call_logis the audit trail the UI will show. Same data, different consumer.
This loop is the entire framework. No AgentExecutor, no Runnable, no compiled graph. Adding a new specialist agent is a system prompt and a list of tools — twenty lines.
The Tool Dataclass#
Tools are described as a tiny dataclass that knows how to render itself as OpenAI's function-spec JSON:
@dataclass class Tool: name: str description: str parameters: dict[str, Any] # JSON schema handler: Callable[..., Any] # called with **args after json-decoding def to_openai(self) -> dict[str, Any]: return { "type": "function", "function": {"name": self.name, "description": self.description, "parameters": self.parameters}, }
The handler is a plain Python callable. The model returns JSON args, the loop json-decodes them and calls the handler with **args. The handler can be a lambda that closes over the database session and the session id, which is exactly what each specialist does. That closure is how I avoid leaking request-scoped state (the SQLAlchemy session, the checkout session id) into the tool's signature.
Specialist 1: Search#
The search agent's job is exactly one thing: turn natural-language intent into one or two semantic queries against the catalog and return product IDs with a short rationale. It has one tool — search_catalog — which runs an embedding query through NIM and asks Milvus for nearest neighbors.
SYSTEM = """You are a retail product search agent for a multi-category storefront. You translate shopper intent into one or two tight semantic queries, call the search_catalog tool, and return the IDs of the most relevant products with a short rationale for each pick. Prefer 3-6 results. Never invent products that aren't in the tool result. If results look weak, refine the query once and retry.""" def _tool_search_catalog(db, query, category=None, top_k=6): vec = embed_texts([query], input_type="query")[0] hits = vector_store.search(vec, top_k=top_k, category=category) products = db.query(Product).filter(Product.id.in_([h["id"] for h in hits])).all() return {"hits": [...]}
Two things matter in that prompt. First, "never invent products" is hallucination prevention — the model has to ground every recommendation in something the tool returned. Second, "refine the query once and retry" opens the door for the tool-calling loop to actually loop. The first query is whatever the shopper said. The second, if needed, is whatever the model thinks would find better matches. With max_iters=4 and a tight schema, this almost never goes more than two turns.
The search_catalog tool itself takes an optional category enum so the model can scope ("ANC headphones" → category=electronics), and top_k so it can ask for more or fewer hits.
Specialist 2: Recommend#
The recommender's job is different in kind from search. It is cart-aware. It needs to know what's already in the basket so it doesn't recommend duplicates, and so it can pick complements ("you have earbuds — here's a travel case, a USB-C cable, a sleep mask").
The architectural question is: where does the cart go? Two options.
- Stuff the cart into the system prompt at each call. Cheap, simple, works.
- Make the cart a tool the agent calls when it wants the data.
I went with option 2 for two reasons. The first is selective loading: most recommend turns need the cart, but a sub-population ("recommend a gift for a five-year-old") don't actually need it — and shouldn't burn tokens carrying twelve cart items through every API call when the agent hasn't decided to use them. The second is uniform interface: making cart context a tool means the promotion agent and the post-purchase agent both consume cart state through the same shape. The agents are interchangeable callers of get_cart_context, with no special-cased prompt formatting.
def run_recommend_agent(db, session_id, user_message): tools = [ Tool( name="get_cart_context", description="Return items currently in this checkout session's cart, with subtotal and categories.", parameters={"type": "object", "properties": {}}, handler=lambda: _cart_context(db, session_id), ), Tool( name="similar_products", description="Find products semantically similar to a theme; excludes items already in cart.", parameters={...}, handler=lambda **kw: _similar_products(db, session_id, **kw), ), ] result = run_agent(SYSTEM, user_message, tools=tools)
Notice that similar_products does the cart-exclusion inside the tool — the agent doesn't have to remember to filter; the tool guarantees it. That's a small reliability win that compounds over weeks of model swaps.
Specialist 3: Promotions#
The promotions agent is the closest thing to a rules engine in the lineup. It has two tools: list_active_promotions (returns the eligibility table) and get_cart_context (returns the current cart and per-category subtotals). The model's job is to pick the single most valuable, eligible promo for the cart and answer in one or two sentences. If nothing is eligible, it should say so plainly and suggest what the shopper would need to add.
SYSTEM = """You are a promotions agent. Call list_active_promotions and get_cart_context, then pick the single most valuable, eligible promo for this cart. Return the promo code and a one-line reason. If no promo is eligible, say so plainly and suggest what they'd need to add to qualify."""
The orchestrator's job after the agent finishes is to extract the chosen code from the reply text and turn it into a structured suggested_promo object that the frontend can render as a one-click "apply" banner. I do this with a heuristic: scan the agent's reply for any known promo code substring and surface the first match. That's deliberately ugly. A cleaner version would use a tool-call return shape ("return the chosen promo as JSON") but I haven't seen the heuristic miss in testing and the simplicity is worth keeping.
Specialist 4: Post-Purchase#
The fourth agent is a support voice. It has one tool — lookup_order — that finds an order by ID or falls back to the most recent order on the current session, and it has a system prompt tuned for empathy.
SYSTEM = """You are a post-purchase support agent. Answer questions about existing orders by calling lookup_order. Be empathetic, concise, and concrete: status, total, tracking, and a clear next step. If the user mentions a return or issue, acknowledge it and outline what they should do next."""
The session-id fallback inside lookup_order is a small affordance that lets a shopper ask "where's my order?" without quoting an order number — the agent finds the most recent order from the current checkout session and answers about that one. In production you'd want this to be customer-id-scoped, not session-scoped; for a demo, session works.
The post-purchase agent never returns products. It never touches Milvus. It is the smallest agent of the four. That's the point — a specialist with the minimum surface needed to do its job.
Why Not LangChain (or LangGraph, or CrewAI, or AutoGen)#
I tried LangChain in 2023 and bounced. I tried LangGraph in 2024 and the abstractions had shifted enough that nothing I wrote in the first attempt was reusable. CrewAI and AutoGen are interesting frameworks but they solve coordination problems I don't have here.
The actual decision tree was:
| Framework feature | Do I need it in Aurora Market? |
|---|---|
| Tool-calling loop | Yes — but it's forty lines I want to own |
| Agent-to-agent messaging | No — agents don't talk to each other |
| Shared scratchpad / blackboard | No — same reason |
| Compiled graph DSL | No — the orchestrator picks N of 4 specialists and runs them in any order |
| Memory / persistence | No — checkout sessions live in SQLite, not in agent state |
| Retry / fallback abstractions | Yes — but tenacity.retry is two lines |
| Streaming primitives | Yes — but I'm streaming SSE to a browser, not framework-internal events |
When the framework's value-add is wiring you don't need and abstractions you'll grow out of, write the loop yourself. Aurora Market's loop is forty lines. The four agents on top of it are about 150 lines combined. The orchestrator is 200. That's the whole agent layer.
Tool-Call Transparency#
The other reason to own the loop: the call_log accumulates every tool name, its args, and a truncated preview of its result. The orchestrator passes that down to the frontend as part of each agent_done SSE event. The frontend renders it as an expandable chip the shopper can open.
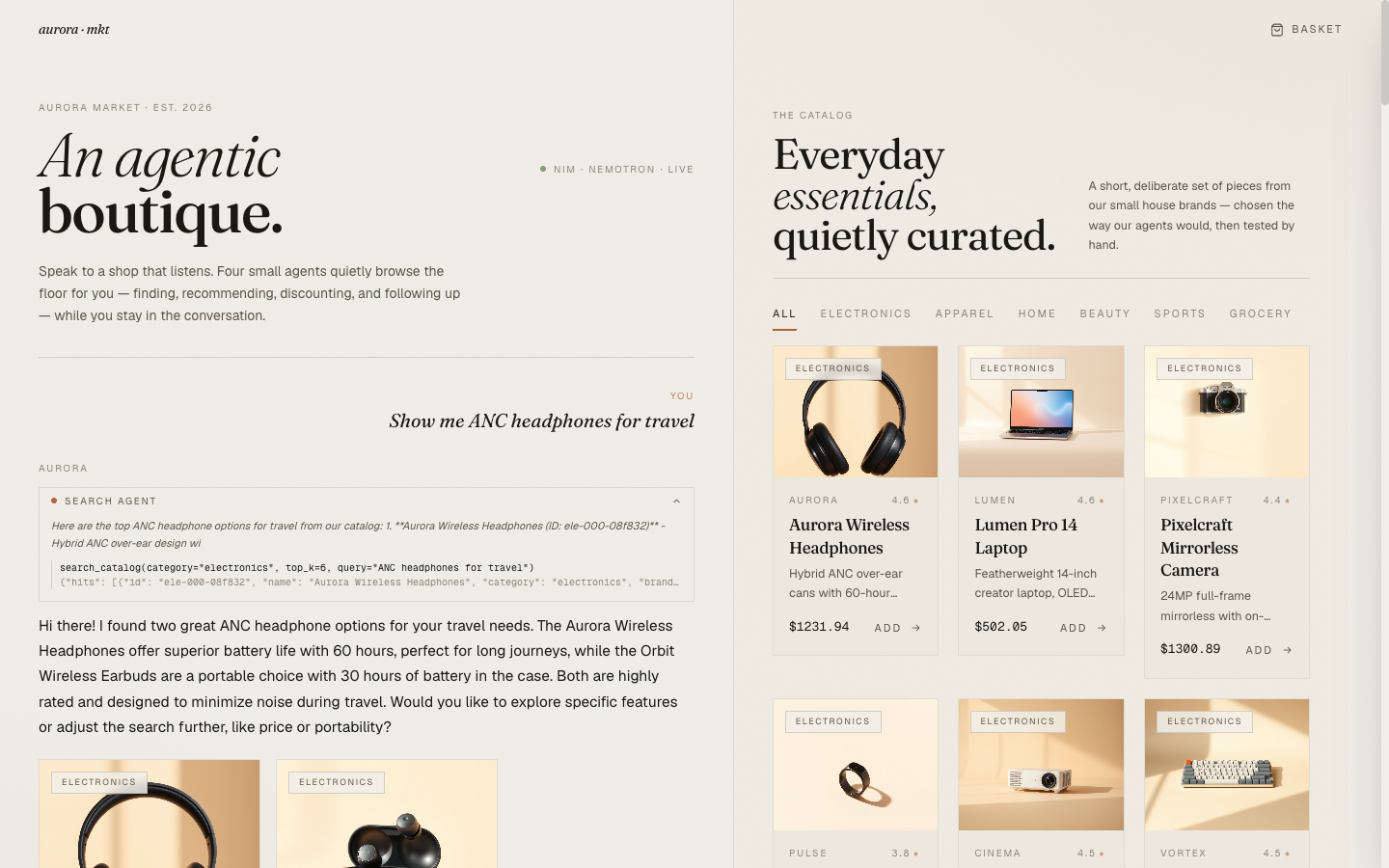
Click "Search agent" and you see the actual function call the agent made, including the rephrased query, the chosen category filter, and a preview of the JSON result. This is the kind of transparency that's invisible if you go through a framework that swallows tool-call telemetry into its own log format. With forty lines of loop, you decide what to surface.
It's also a serious selling point for an agentic commerce demo. Showing the agent's tool call alongside its reply is the difference between "trust me, I'm an AI" and "here's the search I ran, here's what it returned, here's why I picked these three." Blog 6 has the chip rendering details.
What's Next#
Four specialists is the easy half. The hard half is deciding which ones to run for a given turn. The next post is about the orchestrator: a Nemotron router LLM that returns JSON (mostly), a keyword fallback for when it doesn't, and a <think> reasoning-mode bug that produced 23-character reply fragments before I figured out what was eating my max_tokens.