Clinical Research Series — Blog 3: Safety & Hallucination Prevention#
A generic LLM hallucinates 15% of medical facts. Here's how to build guardrails that catch them.
Ask Claude or GPT a medical question without any guardrails, and you'll get a confident, well-structured answer. It will mention studies. It will cite statistics. It will recommend dosages. And roughly one in seven of those claims will be fabricated — a study that doesn't exist, a statistic from a different drug, a dosage pulled from training data patterns rather than actual clinical guidelines.
For a chatbot answering questions about JavaScript frameworks, hallucinations are annoying. For a research tool that clinicians might reference, hallucinations are dangerous. The solution isn't to make the model smarter — it's to build a post-processing safety layer that catches what the model gets wrong.
This post covers three components: a hallucination detector that flags uncited medical claims, a medical credibility scorer that rates every source, and a safety checker that enforces disclaimers and validates the complete response.
The Clinical Research Series#
| Part | Title | Focus |
|---|---|---|
| 1 | Architecture & Domain Analysis | System design, evidence hierarchy, medical APIs |
| 2 | PubMed & ClinicalTrials.gov Integration | E-utilities, v2 API, OpenFDA, circuit breakers |
| 3 | Safety & Hallucination Prevention (this post) | Uncited claim detection, credibility scoring |
| 4 | Evidence Grading & Citation Quality | Level I-V, PMID/NCT citations, journal tiers |
| 5 | Medical Frontend & Production Readiness | Teal theme, EvidencePanel, SafetyAlert |
The Problem: Uncited Medical Claims#
Consider this sentence from a synthesized report: "Studies show that metformin reduces cardiovascular mortality by 30% in patients with Type 2 Diabetes."
Is that true? Maybe. But the report doesn't cite which studies. There's no PMID. No DOI. No way for the reader to verify. The agent might have synthesized this from real PubMed abstracts, or it might have generated it from training data patterns. Without a citation, the reader has no way to distinguish evidence from hallucination.
Our approach is simple: every sentence that makes a medical claim must have a citation. If it doesn't, it gets flagged. The flag includes a severity level — dose recommendations and contraindications are high severity; general study references are medium. The user sees the flags and can decide whether to trust the uncited claim or look it up themselves.
This isn't perfect. A citation doesn't guarantee accuracy — the agent could cite a real PMID but misrepresent its findings. But it's a critical first layer. It shifts the failure mode from "invisible hallucination" to "visible claim that can be verified."
Hallucination Detector: Pattern Matching for Medical Claims#
The hallucination detector scans the synthesized report sentence by sentence, looking for patterns that indicate medical claims. When it finds one without a nearby citation, it flags it.
Claim Detection Patterns#
Medical claims follow recognizable linguistic patterns. "Studies show...", "Research suggests...", "Has been shown to..." — these are the phrases that precede factual assertions that need backing:
# Patterns that indicate medical claims requiring citations _MEDICAL_CLAIM_PATTERNS = [ r"(?:studies?\s+(?:show|suggest|indicate|demonstrate|found|reveal))", r"(?:research\s+(?:shows|suggests|indicates|demonstrates|has\s+found))", r"(?:evidence\s+(?:shows|suggests|indicates|supports))", r"(?:clinical\s+trials?\s+(?:show|suggest|demonstrate|found))", r"(?:according\s+to\s+(?:a\s+)?(?:study|research|trial|analysis))", r"(?:\d+%\s+(?:of\s+)?(?:patients?|subjects?|participants?))", r"(?:(?:significantly|statistically)\s+(?:reduces?|increases?|improves?))", r"(?:has\s+been\s+(?:shown|proven|demonstrated)\s+to)", r"(?:FDA[\s-]approved|clinically\s+proven)", r"(?:recommended\s+(?:dose|dosage|treatment)\s+is)", r"(?:side\s+effects?\s+include)", r"(?:contraindicated\s+(?:in|for))", ]
These patterns cover the most common ways LLMs phrase medical assertions. The percentage pattern (\d+%\s+(?:of\s+)?(?:patients?|subjects?|participants?)) catches specific statistical claims like "65% of patients responded to treatment" — exactly the kind of claim that's easy to fabricate and hard to verify without a source.
Citation Patterns#
For each flagged sentence, the detector checks whether a citation is present:
_CITATION_PATTERNS = [ r"\[(\d+)\]", # [1], [2] r"\(PMID:\s*\d+\)", # (PMID: 12345678) r"PMID\s*\d+", # PMID 12345678 r"NCT\d+", # NCT01234567 r"DOI:\s*\S+", # DOI: 10.xxxx r"\((?:19|20)\d{2}\)", # (2024) ]
We accept multiple citation formats because the synthesis agent isn't always consistent. Sometimes it uses bracket references [1], sometimes inline PMIDs, sometimes NCT IDs for trial references. As long as any citation format appears in the sentence, we consider the claim cited.
The year-in-parentheses pattern \((?:19|20)\d{2}\) is the most permissive — we accept "(2024)" as a minimal citation. This catches academic-style references like "Smith et al. (2023) found..." without requiring a full PMID.
The Detection Loop#
The core detection logic splits the report into sentences, checks each one for claim patterns, and flags any that lack citations:
@dataclass class HallucinationFlag: """A flagged medical claim that may lack citation.""" sentence: str claim_type: str has_citation: bool severity: str # "high" (dose/treatment), "medium" (study claim), "low" (general) suggestion: str def detect_hallucinations(report: str) -> list[HallucinationFlag]: """Scan a medical report for claims that lack citations.""" flags = [] sentences = re.split(r"(?<=[.!?])\s+", report) for sentence in sentences: sentence = sentence.strip() if len(sentence) < 20: continue # Check if sentence contains a medical claim pattern claim_type = _detect_claim_type(sentence) if not claim_type: continue # Check if sentence has a citation nearby has_citation = bool(re.search("|".join(_CITATION_PATTERNS), sentence)) if not has_citation: severity = _classify_severity(claim_type) flags.append(HallucinationFlag( sentence=sentence[:200], claim_type=claim_type, has_citation=False, severity=severity, suggestion=_get_suggestion(claim_type, severity), )) return flags
The 20-character minimum filters out sentence fragments and markdown artifacts. The sentence[:200] truncation keeps flag data manageable for the frontend.
Claim Classification and Severity#
Not all uncited claims are equally dangerous. A missing citation on "studies suggest this drug may be helpful" is concerning. A missing citation on "the recommended dose is 500mg twice daily" is dangerous. The severity system reflects this:
def _detect_claim_type(sentence: str) -> str: """Detect what type of medical claim the sentence makes.""" s_lower = sentence.lower() if re.search(r"(?:recommended\s+dose|dosage|mg\s*(?:per|/)\s*(?:day|kg))", s_lower): return "dose_recommendation" if re.search(r"(?:contraindicated|should\s+not\s+(?:be\s+)?(?:used|taken|administered))", s_lower): return "contraindication" if re.search(r"(?:side\s+effects?\s+include|adverse\s+(?:effects?|reactions?))", s_lower): return "side_effects" if re.search(r"(?:FDA[\s-]approved|clinically\s+proven)", s_lower): return "approval_claim" for pattern in _MEDICAL_CLAIM_PATTERNS: if re.search(pattern, s_lower): return "study_claim" return "" def _classify_severity(claim_type: str) -> str: """Classify the severity of an uncited claim.""" if claim_type in ("dose_recommendation", "contraindication", "approval_claim"): return "high" elif claim_type in ("side_effects", "study_claim"): return "medium" return "low"
The ordering in _detect_claim_type matters. Dose recommendations are checked first because a sentence like "The recommended dose is 500mg per day, as studies have shown..." should be classified as a dose recommendation (high severity), not a study claim (medium severity). The more specific, more dangerous patterns take priority.
Actionable Suggestions#
Each severity level gets a specific, actionable suggestion:
def _get_suggestion(claim_type: str, severity: str) -> str: if severity == "high": return "This claim requires a citation. Add a PMID or remove the specific recommendation." elif severity == "medium": return "This study-level claim should reference a specific source (PMID or DOI)." return "Consider adding a citation to support this statement."
High-severity suggestions are explicit: "Add a PMID or remove the specific recommendation." The "or remove" part is important. Sometimes the right fix isn't to find a citation — it's to not make the claim at all. The agent should never recommend specific doses.
Medical Credibility Scorer: Not All Sources Are Equal#
Even with citations, source quality matters. A claim cited to the New England Journal of Medicine carries more weight than a claim cited to a health blog. The credibility scorer assigns a 0-100 score to every source based on its type, journal, and domain.
The Tier System#
Sources are organized into tiers:
# High-impact medical journals _TIER1_JOURNALS = { "the lancet", "new england journal of medicine", "nejm", "jama", "bmj", "nature medicine", "nature", "science", "cell", "annals of internal medicine", "circulation", "journal of clinical oncology", "the lancet oncology", "lancet infectious diseases", "plos medicine", } # Government and institutional sources _TIER1_DOMAINS = { "nih.gov", "cdc.gov", "who.int", "fda.gov", "clinicaltrials.gov", "cochranelibrary.com", "ncbi.nlm.nih.gov", "pubmed.ncbi.nlm.nih.gov", } # Reputable medical sites _TIER2_DOMAINS = { "mayoclinic.org", "uptodate.com", "medscape.com", "webmd.com", "clevelandclinic.org", "hopkinsmedicine.org", "healthline.com", } # Preprint servers _PREPRINT_DOMAINS = { "medrxiv.org", "biorxiv.org", "arxiv.org", "preprints.org", }
Scoring Logic#
The scoring function checks source type first (PubMed, ClinicalTrials, OpenFDA), then falls through to domain-based scoring for web sources:
@tool def score_medical_credibility(url: str, source_type: str, journal: str = "", domain: str = "") -> dict: """Score the credibility of a medical source.""" domain_lower = domain.lower() if domain else "" journal_lower = journal.lower() if journal else "" # PubMed articles — high baseline credibility if source_type == "pubmed": if any(j in journal_lower for j in _TIER1_JOURNALS): return _result(url, 98, "tier1_journal", "High-impact peer-reviewed journal", "Safe to cite") return _result(url, 90, "peer_reviewed", "Peer-reviewed article indexed in PubMed", "Safe to cite") # Clinical trial registries if source_type == "clinicaltrials": return _result(url, 92, "trial_registry", "Registered clinical trial on ClinicalTrials.gov", "Safe to cite") # FDA data if source_type == "openfda": return _result(url, 95, "government", "Official FDA adverse event data", "Safe to cite") # Preprints — moderate credibility with warning if source_type == "preprint" or any(d in domain_lower for d in _PREPRINT_DOMAINS): return _result(url, 55, "preprint", "Preprint — not yet peer-reviewed", "Cite with caution — not peer-reviewed") # Government/institutional domains if any(d in domain_lower for d in _TIER1_DOMAINS): return _result(url, 93, "government", "Government or institutional source", "Safe to cite") # Reputable medical sites if any(d in domain_lower for d in _TIER2_DOMAINS): return _result(url, 70, "medical_site", "Reputable medical information site", "Requires context") # Unknown web sources if domain_lower.endswith(".edu"): return _result(url, 80, "academic", "Academic institution", "Safe to cite") return _result(url, 40, "unverified", "Unverified web source", "Use caution — verify independently")
The score breakdown tells you everything about the design philosophy:
| Source Type | Score | Recommendation |
|---|---|---|
| Tier 1 journal (NEJM, Lancet, JAMA) | 98 | Safe to cite |
| OpenFDA (government data) | 95 | Safe to cite |
| Government domains (NIH, CDC, WHO) | 93 | Safe to cite |
| ClinicalTrials.gov registry | 92 | Safe to cite |
| Any PubMed-indexed article | 90 | Safe to cite |
| Academic (.edu) domains | 80 | Safe to cite |
| Medical sites (Mayo, UpToDate) | 70 | Requires context |
| Preprints (medRxiv, bioRxiv) | 55 | Cite with caution |
| Unverified web sources | 40 | Verify independently |
The gap between PubMed (90) and preprints (55) is intentional and large. A preprint on medRxiv might contain groundbreaking research, but it hasn't been peer-reviewed. During COVID-19, preprints claiming hydroxychloroquine efficacy circulated widely before peer review found fatal methodological flaws. The 55 score doesn't mean "don't cite" — it means "cite with an explicit caveat."
The 40-point floor for unverified web sources means the agent never fully trusts an unknown source, but still includes it with appropriate warnings. This is better than binary accept/reject — it gives the user information to make their own judgment.
Safety Checker: The Final Gate#
The safety checker is the last step before a response reaches the user. It aggregates hallucination flags, checks for disclaimer presence, and produces a pass/fail safety verdict:
MEDICAL_DISCLAIMER = ( "**Disclaimer:** This is an AI-powered research tool for informational purposes only. " "It is NOT a substitute for professional medical advice, diagnosis, or treatment. " "Always consult a qualified healthcare provider for medical decisions." ) @dataclass class SafetyCheckResult: """Result of a safety check on a research response.""" is_safe: bool disclaimer_present: bool warnings: list[str] hallucination_count: int high_severity_count: int
The Safety Logic#
The checker runs four validation passes:
def check_safety( report: str, hallucination_flags: list = None, sources_count: int = 0, ) -> SafetyCheckResult: """Run safety checks on a research response.""" warnings = [] flags = hallucination_flags or [] high_severity = sum(1 for f in flags if f.severity == "high") # Check for sources if sources_count == 0: warnings.append("No sources cited — research may be based on model knowledge only") # Check for high-severity hallucinations if high_severity > 0: warnings.append(f"{high_severity} high-severity uncited medical claim(s) detected") # Check for dose recommendations report_lower = report.lower() if any(term in report_lower for term in ["recommended dose", "take", "mg per day", "mg/kg"]): if "disclaimer" not in report_lower: warnings.append("Report contains dose information without disclaimer") # Check disclaimer disclaimer_present = "not a substitute" in report_lower or "not medical advice" in report_lower is_safe = high_severity == 0 and len(warnings) <= 1 return SafetyCheckResult( is_safe=is_safe, disclaimer_present=disclaimer_present, warnings=warnings, hallucination_count=len(flags), high_severity_count=high_severity, )
The is_safe logic is conservative: the response is only marked safe if there are zero high-severity hallucination flags AND at most one warning. This means a response with zero sources is not automatically unsafe (it gets one warning), but a response with zero sources AND a dose recommendation IS unsafe (two warnings).
The Four Checks#
-
Source check: If
sources_count == 0, the response is based entirely on model knowledge — no PubMed articles, no trials, no FDA data. This might happen if all three APIs are down (circuit breakers tripped). The user needs to know. -
Hallucination severity check: Any high-severity uncited claim (dose recommendation, contraindication, FDA approval claim) triggers a warning. Even one is enough to mark the response as potentially unsafe.
-
Dose detection: A separate scan for dose-related keywords. Even if the hallucination detector didn't flag a specific sentence, the presence of dose information without a disclaimer is a safety concern. The agent is explicitly instructed never to recommend doses, but this is a defense-in-depth check.
-
Disclaimer verification: The response must contain the medical disclaimer. The orchestrator appends it automatically, but the safety checker verifies — because a bug in the pipeline could silently drop it.
How It Flows in the Pipeline#
In the orchestrator, the safety layer runs after synthesis is complete:
# Step 7: Hallucination detection hallucination_flags = detect_hallucinations(full_report) # Step 8: Safety check safety_result = check_safety( report=full_report, hallucination_flags=hallucination_flags, sources_count=len(unique_sources), ) # Emit safety event to frontend yield { "type": "safety", "flags": [ { "sentence": f.sentence[:150], "claim_type": f.claim_type, "severity": f.severity, "suggestion": f.suggestion, } for f in hallucination_flags ], "disclaimer": MEDICAL_DISCLAIMER, "is_safe": safety_result.is_safe, "warnings": safety_result.warnings, } # Step 9: Append disclaimer (always) disclaimer_text = f"\n\n---\n\n{MEDICAL_DISCLAIMER}" yield {"type": "text", "data": disclaimer_text}
The safety event is emitted as a structured WebSocket event, separate from the report text. The frontend renders it as an alert panel — yellow for warnings, red for unsafe responses. The user sees the specific uncited claims, their severity, and actionable suggestions.
Real Example: Safety Alert in Action#
Here's what the safety layer catches in practice. The agent researches "metformin cardiovascular effects" and the synthesized report contains:
"Studies demonstrate that metformin significantly reduces cardiovascular mortality in patients with Type 2 Diabetes."
The hallucination detector flags this:
- Claim type:
study_claim - Severity:
medium - Has citation:
false - Suggestion: "This study-level claim should reference a specific source (PMID or DOI)."
And if the report also contains:
"The recommended dose is 500mg twice daily, titrated to 2000mg."
That gets a different flag:
- Claim type:
dose_recommendation - Severity:
high - Has citation:
false - Suggestion: "This claim requires a citation. Add a PMID or remove the specific recommendation."
The frontend renders these as a safety alert panel:
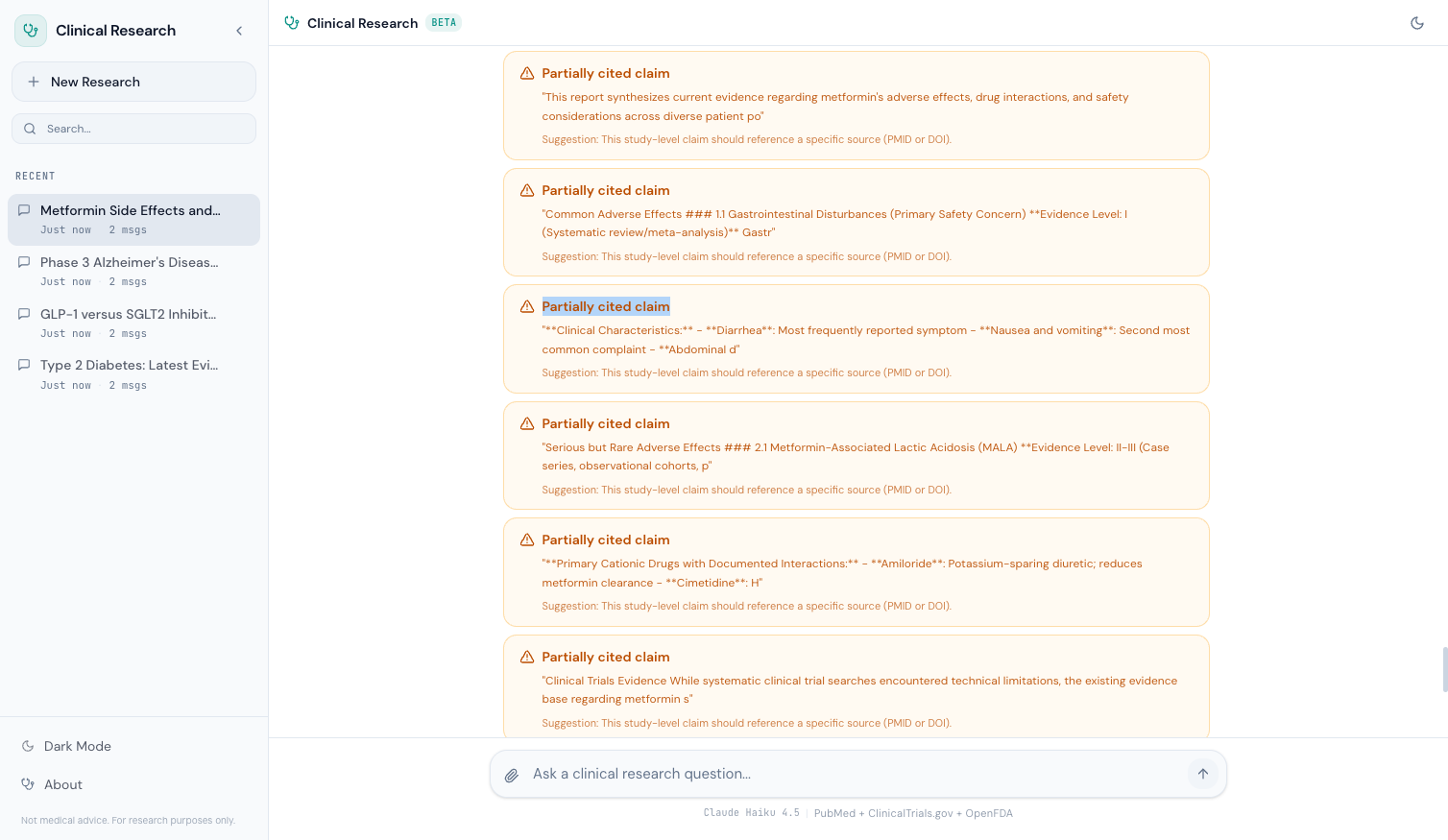
The high-severity flag on the dose recommendation is what makes the overall response marked as is_safe: false. The user sees the alert, understands which claims are unverified, and can make an informed decision about how to use the information.
The Principle: Better to Say "Insufficient Evidence"#
The entire safety layer is built on one principle: it's better for the agent to say "insufficient evidence" than to present an unverified claim as fact.
A generic AI assistant optimizes for helpfulness — it tries to answer every question as completely as possible. A medical research tool must optimize for accuracy and transparency. An incomplete answer with proper citations is more valuable than a complete answer with fabricated ones.
This means:
- If PubMed returns no results, the agent says "no peer-reviewed literature was found" rather than synthesizing from training data
- If a claim can't be traced to a specific PMID, it gets flagged rather than silently included
- If a dose is mentioned, it gets a warning even if it's technically correct
- Every response ends with a disclaimer, every time, no exceptions
The safety layer doesn't make the agent perfect. It makes the agent honest about its limitations. And in medicine, honesty about uncertainty is more valuable than false confidence.
What's Next#
We've built the safety net. In Blog 4 (coming soon), we'll dive into the evidence grading pipeline — how the system classifies each PubMed article into evidence levels I through V, how parallel researchers dispatch across sub-queries, and how the critique agent reviews findings before synthesis. The safety layer catches problems after synthesis; evidence grading prevents them before synthesis by ensuring the agent knows the difference between a Cochrane review and a case report.
All code is open source: github.com/MinhQuanBuiSco/clinical-research-agent