🤝 The Customer#
I was embedded as a forward-deployed engineer at a regulated financial-services client — a large insurance provider. The teams needed trustworthy, grounded answers from a large and growing body of internal documents, and the managed search tooling they'd reached for was getting expensive fast as usage scaled.
The barriers behind the ask:
• 🎭 Hallucination Issues: Standard LLMs generate plausible but incorrect information
• 🔒 Context Limitations: Models lack access to proprietary organizational knowledge
• 💰 Expensive Solutions: AWS Kendra costs escalate rapidly with enterprise usage
• 📈 Scaling Challenges: Traditional search solutions don't scale cost-effectively
• 🎯 Accuracy Gaps: Generic models underperform on organization-specific queries
🔍 Discovery#
Before proposing anything, I ran discovery with the client's stakeholders — scoping requirements and mapping the real query patterns against the document corpus. The goal was to separate the problem they thought they had (better search) from the one they actually had: grounded, affordable answers at organization scale, inside a regulated environment.
🧪 The Proof-of-Concept#
To de-risk the direction before any big commitment, I built a POC with an evaluation suite that demonstrated equivalent retrieval quality on a representative slice of their corpus — before the client committed. It proved two things at once: the retrieval quality they needed and that we could hit it without a Kendra-heavy bill.
🧭 The Recommendation & The Negotiation#
The default expectation was AWS Kendra. I advised the opposite: replace managed Kendra with self-hosted Aurora + OpenSearch Serverless on Bedrock as the retrieval backbone, reserving Kendra for the <5% of specialized queries that justified it.
That meant handling the natural objection — isn't managed Kendra the safer, lower-effort bet? I let the evaluation suite answer it: the POC numbers showed equivalent quality, and the cost curve at their projected scale showed the gap only widening. With the evidence on the table, the stakeholders aligned on the self-hosted-retrieval path — 40% lower cost at equal performance.
📦 The Result#
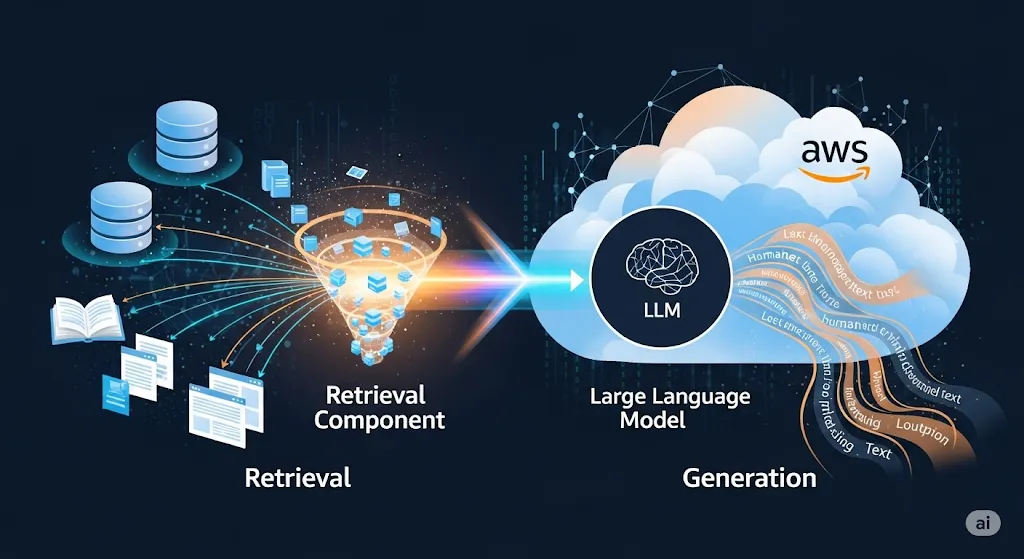
The system shipped to production and now serves the organization at scale: 40% cost reduction, 30% accuracy improvement, and 99.9% uptime — grounded answers on proprietary data, delivered inside a regulated financial environment. The full architecture is below.
💡 How It Was Built#
Engineered a cost-optimized RAG architecture that delivers enterprise-grade performance at 40% lower cost:
🏗️ Smart Cost Architecture
• OpenSearch Serverless → Primary vector search replacing expensive Kendra
• Aurora Database → Cost-effective vector storage and structured data management
• Strategic Kendra Usage → Limited to <5% of specialized queries only
• 40% Cost Reduction → Dramatic infrastructure savings while improving performance
🚀 Advanced Processing Pipeline
• AWS Comprehend → Intelligent metadata extraction and entity recognition
• Titan Embedding → High-quality vector representations for semantic search
• Bedrock Foundation Models → State-of-the-art text generation capabilities
• 30% Accuracy Improvement → Enhanced response quality through optimized retrieval
Cost-Optimized AWS Service Integration
- OpenSearch Serverless: Primary vector search engine replacing expensive Kendra, reducing search costs dramatically
- Aurora Database: Cost-effective vector storage and structured data management
- AWS Comprehend: Advanced metadata extraction and entity recognition
- AWS Bedrock (Titan): Text embedding model for vector generation
- AWS Kendra: Minimal integration for specialized document types only (< 5% of queries)
- Bedrock: Foundation models for text generation
RAG Pipeline
The system implements a sophisticated Retrieval-Augmented Generation pipeline:

- Document Ingestion: Automated processing and indexing of enterprise documents
- Metadata Extraction: AWS Comprehend analyzes documents for entities, sentiment, and key phrases
- Vector Generation: Titan embedding model converts documents into high-dimensional vectors
- Cost-Effective Storage: Aurora database serves as primary vector storage, reducing costs significantly
- Query Processing: Intelligent query understanding and expansion via Titan embeddings
- Hybrid Retrieval: OpenSearch Serverless handles 95% of vector searches with Aurora backend, minimal Kendra usage for specialized content
- Generation Phase: Context-aware response generation using retrieved information via Bedrock
Cost Optimization & Performance
- 40% cost reduction by using OpenSearch Serverless + Aurora instead of Kendra-heavy architecture
- Implemented distributed processing for large-scale data handling at lower cost
- Optimized vector embeddings for fast semantic search using Aurora's cost-effective storage
- Serverless architecture eliminates idle time costs, scaling down to zero when not in use
Cost-Effective Vector Architecture
- OpenSearch Serverless Optimization: Developed custom embedding strategies optimized for serverless cost structure
- Aurora Integration: Implemented efficient vector storage in Aurora, providing cost-effective data persistence
- Hybrid Search Strategy: Combined OpenSearch Serverless vector search with minimal Kendra usage achieving 40% cost reduction
- Smart Indexing: Created efficient indexing methods that minimize expensive service calls
Economic Performance Architecture
- Intelligent Caching: Built distributed caching system reducing expensive service calls
- Serverless Scaling: Implemented automatic scaling that chooses cost-effective service combinations
- Connection Optimization: Optimized database connections to Aurora for maximum cost efficiency
- Pay-per-use Model: Leveraged OpenSearch Serverless to pay only for actual usage, eliminating idle costs
Production Readiness
- Designed fault-tolerant architecture with automatic failover
- Implemented comprehensive monitoring and alerting
- Built secure access controls and audit logging
- Created disaster recovery procedures
Performance & Cost Metrics
- 30% improvement in response accuracy over baseline models
- 40% cost reduction compared to Kendra-heavy implementations
- Sub-second latency for most queries using optimized OpenSearch Serverless + Aurora
- 99.9% uptime in production environment
- Scalable to organization-wide concurrent users at 40% lower infrastructure cost
Impact & Results#
This cost-optimized RAG system has transformed both the organization's knowledge management and budget efficiency:
- Significant Cost Savings: 40% reduction in infrastructure costs while maintaining performance
- Enhanced Decision Making: More accurate and context-aware AI responses
- Reduced Hallucinations: Grounded responses based on proprietary data using cost-effective retrieval
- Budget-Friendly Scaling: Successfully deployed across multiple business units without budget constraints
- ROI Achievement: Positive return on investment within 6 months due to cost optimization
The system processes thousands of queries daily using OpenSearch Serverless and Aurora, proving that high-quality AI can be both effective and economical.
Key Achievements
40% cost reduction vs. Kendra-heavy setup
30% better response accuracy
Positive ROI within 6 months of launch
Replaced expensive Kendra with OpenSearch Serverless and Aurora optimization, delivering a budget-friendly, enterprise-ready system that scales to organization-wide usage