Building a Multi-Model LLM Router: Intelligent Query Routing for Cost Optimization on Azure#
Not every question deserves a frontier model. Asking GPT-4.1 to say "Hello" is like hiring a neurosurgeon to apply a band-aid. Yet most LLM-powered applications route every query to the same expensive model, burning through budget on trivial tasks while gaining nothing in quality.
In this tutorial, I'll walk through how I built a Multi-Model LLM Router that analyzes each incoming query's complexity and category, then routes it to the cheapest model tier capable of handling it well. The result: 59% cost savings with no perceptible drop in response quality.
Live Demo#
Here's the dashboard showing real routing decisions across all three model tiers:
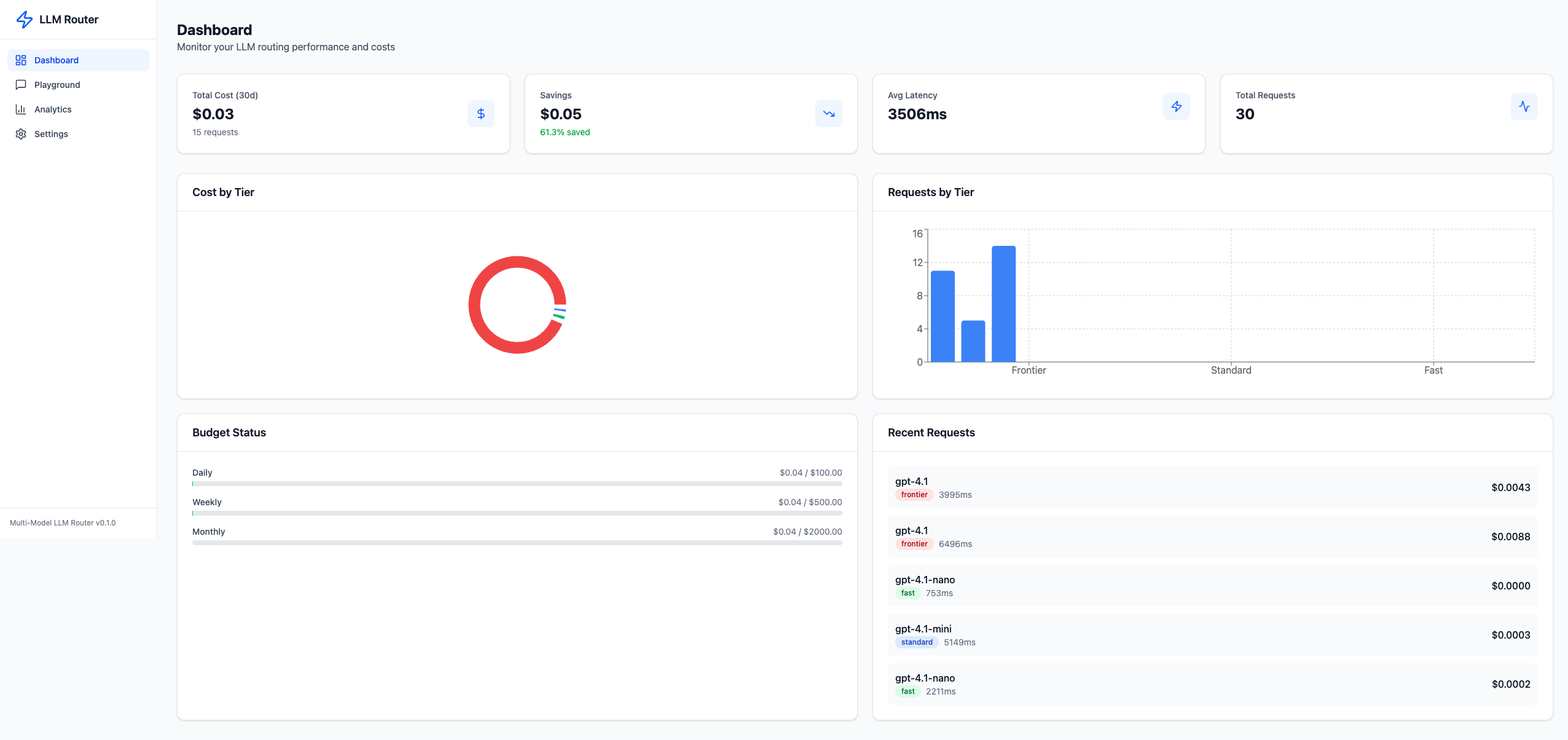
The dashboard surfaces total cost, savings percentage, average latency, request volume, cost breakdown by tier, budget tracking, and a live feed of recent routing decisions.
The Problem: One Model Doesn't Fit All#
Consider these three queries:
| Query | What It Needs | Best Tier |
|---|---|---|
| "Hello, how are you?" | Pattern matching | Fast (GPT-4.1 Nano) |
| "Write a Python function to sort a list" | Code generation | Standard (GPT-4.1 Mini) |
| "Explain quantum entanglement implications for computing" | Deep reasoning | Frontier (GPT-4.1) |
Sending all three to GPT-4.1 costs $10/1M tokens (input + output). Routing intelligently drops that to a blended rate under $4/1M tokens for typical workloads.
Model Tiers and Pricing#
| Tier | Model | Input ($/1M tokens) | Output ($/1M tokens) | Use Case |
|---|---|---|---|---|
| Frontier | GPT-4.1 | $2.00 | $8.00 | Complex reasoning, research, math |
| Standard | GPT-4.1 Mini | $0.40 | $1.60 | General tasks, coding, creative |
| Fast | GPT-4.1 Nano | $0.10 | $0.40 | Simple chat, greetings, lookups |
The price difference between Frontier and Fast is 20x on input and 20x on output. Routing even 30% of traffic to lower tiers produces massive savings.
System Architecture#
The router sits between the client and model providers as a transparent proxy. From the outside, it's an OpenAI-compatible /v1/chat/completions endpoint. Internally, it runs a multi-stage analysis pipeline before selecting a model.
Client Request
|
v
+------------------+
| FastAPI Server |
+------------------+
|
v
+------------------+ +------------------+
| Complexity | --> | Semantic |
| Analyzer | | Classifier |
| (0-100 score) | | (7 categories) |
+------------------+ +------------------+
| |
v v
+--------------------------------------+
| Model Selector |
| Combines signals -> picks tier |
| Selects cheapest model in tier |
+--------------------------------------+
|
v
+------------------+ +------------------+
| Budget | --> | Azure OpenAI |
| Controller | | Provider |
| (Redis-backed) | | (Foundry) |
+------------------+ +------------------+
| |
v v
+--------------------------------------+
| Cosmos DB Logging |
| (routing logs, analytics, costs) |
+--------------------------------------+
Key Infrastructure#
- FastAPI backend with async support and streaming
- Redis for real-time budget tracking and routing cache
- Azure Cosmos DB for persistent logging, analytics, and budget configurations
- Azure Container Apps for horizontally scalable deployment (1-10 replicas)
- Terraform for infrastructure-as-code
Deep Dive: The Routing Pipeline#
Step 1: Complexity Analysis#
The ComplexityAnalyzer scores every query on a 0-100 scale using five weighted components:
class ComplexityAnalyzer: TOKEN_WEIGHT = 0.15 # How long is the query? VOCABULARY_WEIGHT = 0.20 # How sophisticated is the language? QUESTION_DEPTH_WEIGHT = 0.25 # "why/explain/analyze" vs "what is/define" DOMAIN_WEIGHT = 0.20 # Technical terms (quantum, algorithm, etc.) MULTISTEP_WEIGHT = 0.20 # Multiple questions, step-by-step requests
Each component produces a 0-100 sub-score:
Token Score (15%) — longer queries tend to be more complex:
def _calculate_token_score(self, text: str) -> float: token_count = self._count_tokens(text) # Uses tiktoken if token_count < 50: return 10 elif token_count < 100: return 25 elif token_count < 200: return 40 elif token_count < 500: return 60 elif token_count < 1000: return 80 else: return 100
Question Depth (25%) — the highest-weighted signal. Deep indicators like "why", "explain", "analyze", "implications" score high. Shallow indicators like "what is", "define", "list" score low:
DEEP_QUESTION_PATTERNS = [ r"\bwhy\b", r"\bhow\s+does\b", r"\bexplain\b", r"\banalyze\b", r"\bcompare\b", r"\bimplications?\b", ] SHALLOW_QUESTION_PATTERNS = [ r"\bwhat\s+is\b", r"\bwho\s+is\b", r"\bdefine\b", r"\blist\b", ]
Domain Specificity (20%) — matches against curated term lists across five domains: programming (algorithm, kubernetes, neural network), science (quantum, molecular), math (eigenvalue, topology), legal (jurisdiction, statute), and medical (pathology, pharmacology).
Vocabulary Score (20%) — measures average word length, unique-word ratio, and proportion of long words (>7 characters).
Multi-step Score (20%) — detects patterns like "step by step", multiple question marks, numbered lists, and conjunctions like "additionally" or "furthermore".
The final score maps directly to tiers:
- 0-30: Fast tier
- 31-70: Standard tier
- 71-100: Frontier tier
Step 2: Semantic Classification#
The SemanticRouter classifies queries into seven categories using keyword matching:
CATEGORY_TIER_MAP = { QueryCategory.CHAT: ModelTier.FAST, # Greetings, small talk QueryCategory.QA: ModelTier.STANDARD, # General questions QueryCategory.CODING: ModelTier.STANDARD, # Code tasks QueryCategory.REASONING: ModelTier.FRONTIER, # Deep analysis QueryCategory.CREATIVE: ModelTier.STANDARD, # Writing, stories QueryCategory.MATH: ModelTier.FRONTIER, # Mathematical problems QueryCategory.RESEARCH: ModelTier.FRONTIER, # Research tasks }
This is keyword-based rather than ML-based intentionally — it's fast, deterministic, interpretable, and requires zero inference cost.
Step 3: Model Selection#
The ModelSelector combines both signals using a tiered decision algorithm:
def _combine_tier_signals(self, complexity_tier, category_tier, complexity_score): # Strong signals override everything if complexity_score <= 15: return ModelTier.FAST, "Very low complexity - simple query" if complexity_score >= 85: return ModelTier.FRONTIER, "Very high complexity" # Category acts as a MINIMUM FLOOR # Never route below what the category requires if category_idx > complexity_idx: return category_tier, f"Category requires {category_tier.value} model" # Average the signals for middle ground avg_idx = (complexity_idx + category_idx) / 2 if avg_idx < 0.75: return ModelTier.FAST elif avg_idx < 1.5: return ModelTier.STANDARD else: return ModelTier.FRONTIER
The key insight: category acts as a floor, not a ceiling. A short query like "solve x^2 + 3x - 4 = 0" has low token complexity but is categorized as MATH, which requires the Frontier tier. The category signal prevents it from being routed to the Fast tier where GPT-4.1 Nano would produce unreliable math results.
Seeing It in Action#
Simple Chat Query → Fast Tier#
Sending "Hello, how are you today?" through the playground:
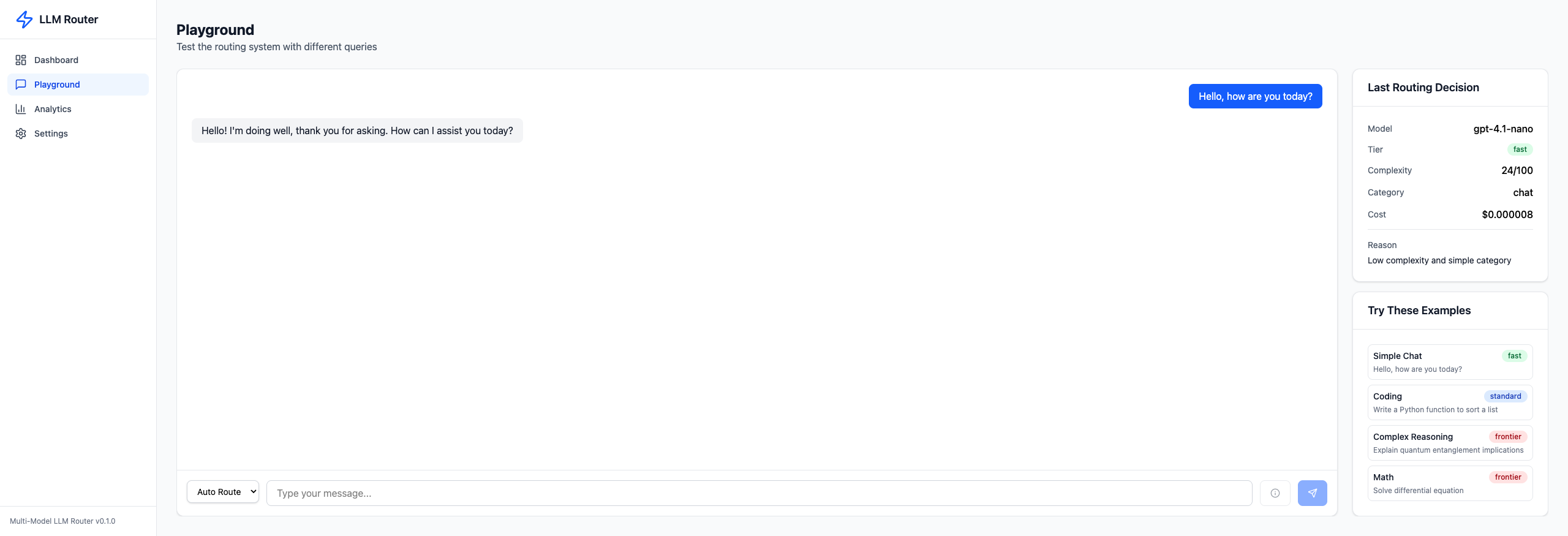
The router assigned gpt-4.1-nano (Fast tier) with a complexity score of 24/100. Cost: $0.000008. The routing reason: "Low complexity and simple category".
Complex Reasoning Query → Frontier Tier#
Sending "Explain the implications of quantum entanglement for quantum computing":
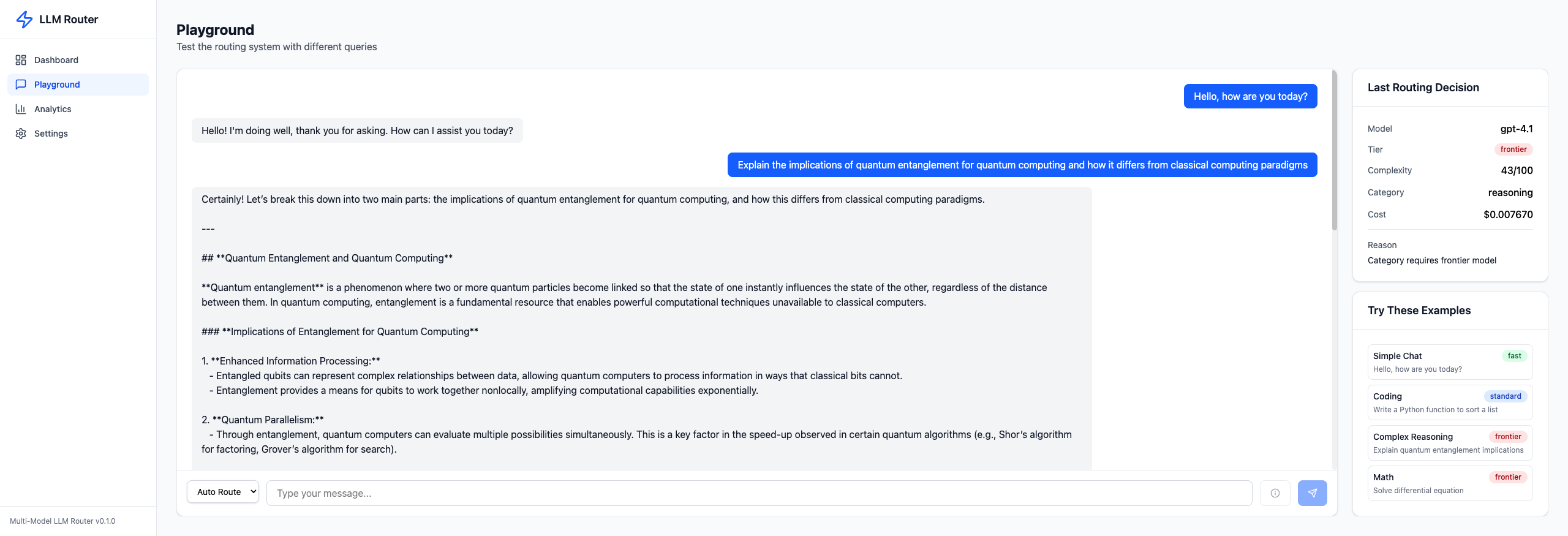
Despite a moderate complexity score of 43/100, the semantic classifier detected "reasoning" as the category, which requires the Frontier tier. The category floor kicked in: "Category requires frontier model". Cost: $0.007670 — 1000x more than the chat query, but appropriate for the task.
Routing Preview#
Before committing to a request, you can preview the routing decision with a full complexity breakdown:
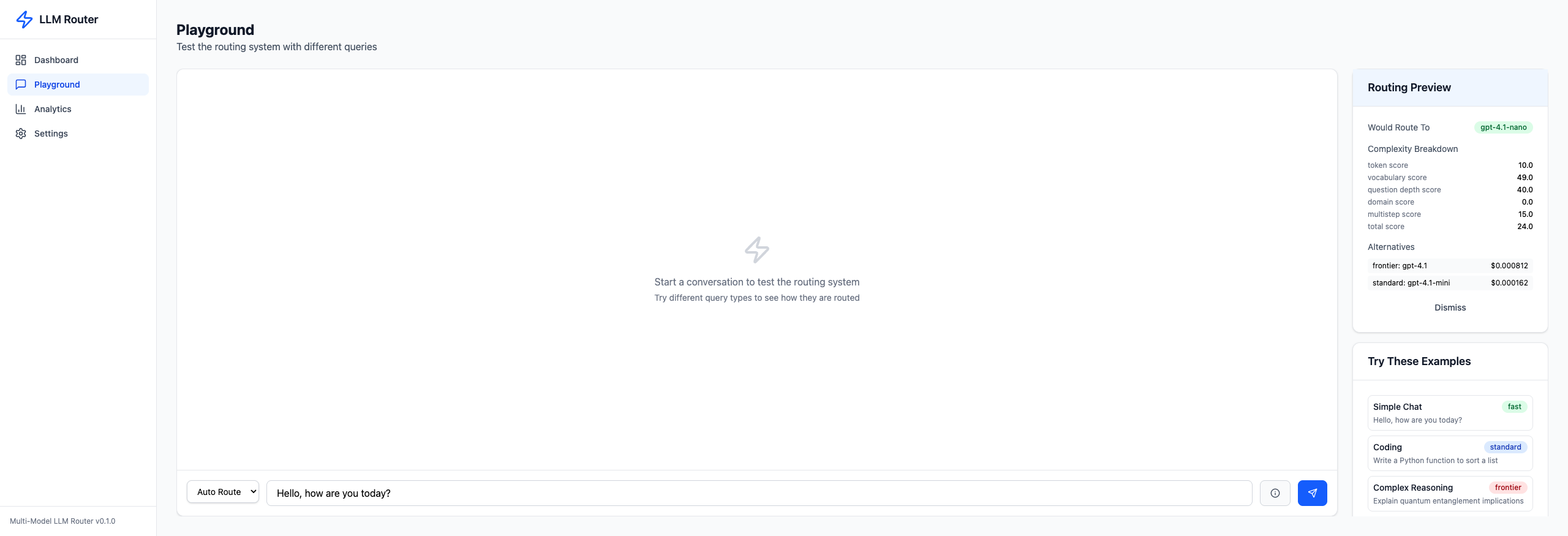
The preview shows the target model, all five complexity sub-scores, the total score, and alternative models with estimated costs. This transparency makes the routing logic auditable and debuggable.
Budget Controls#
The system enforces budget limits at three time scales with configurable thresholds:
# Default budget limits default_daily_budget = 100.0 # $100/day default_weekly_budget = 500.0 # $500/week default_monthly_budget = 2000.0 # $2,000/month # Alert thresholds: warn at 50%, 75%, and 90% alert_thresholds = [0.5, 0.75, 0.9]
Budget tracking uses Redis for real-time atomic increments (INCRBYFLOAT), with Cosmos DB for historical aggregation. When hard_limit is enabled, requests that would exceed the budget are blocked with a 429 response.
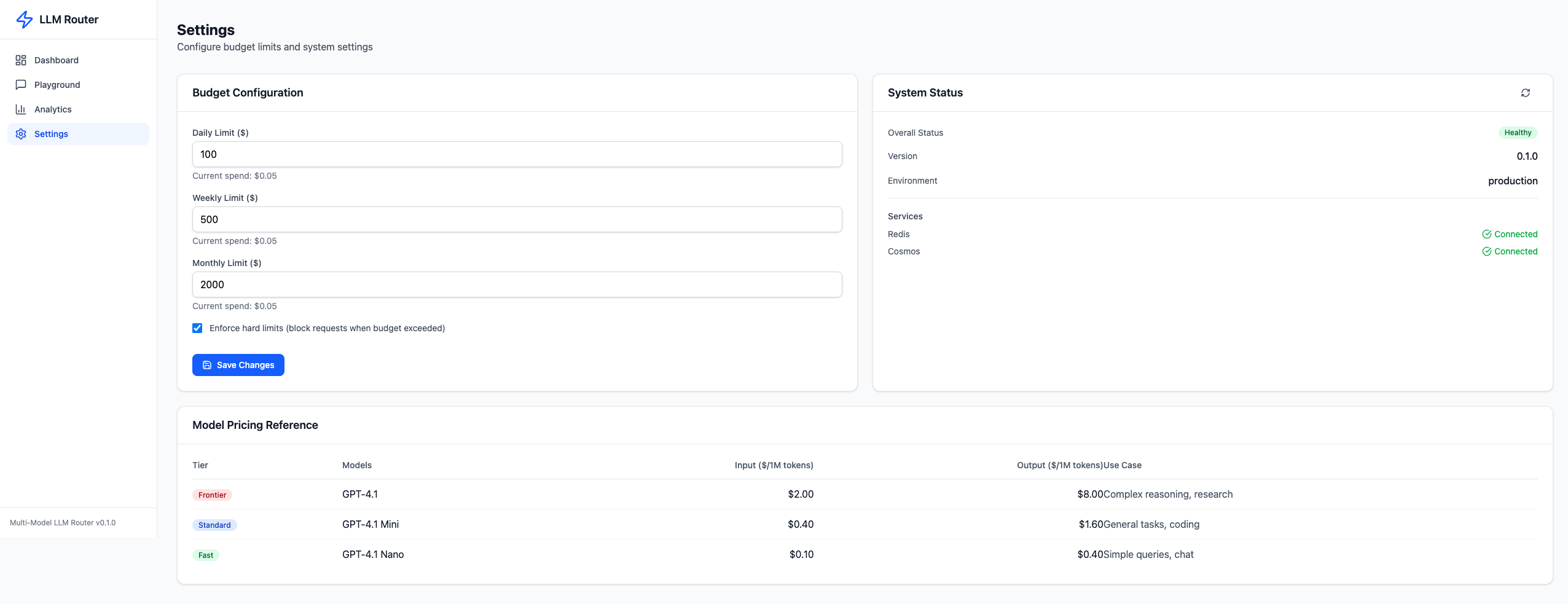
The Settings page shows budget configuration, system health (Redis and Cosmos DB connection status), and the model pricing reference table.
Analytics and Cost Tracking#
The analytics dashboard provides full visibility into routing behavior and cost savings:
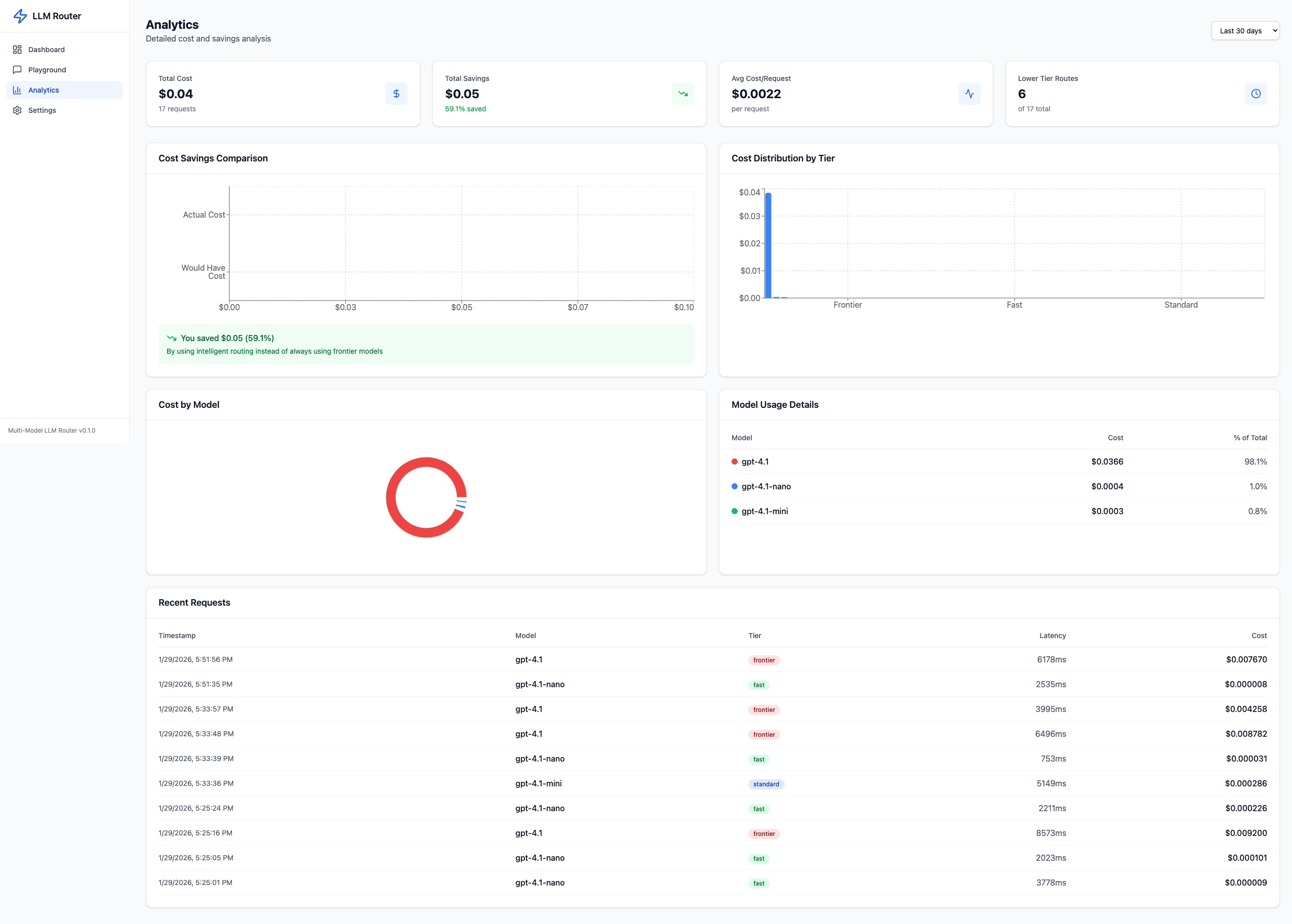
The analytics view shows actual cost vs. what you would have paid using only Frontier models, cost distribution by tier, per-model breakdowns, and a request-level audit trail with timestamps, models, tiers, latencies, and costs.
Key metrics from the live deployment:
- Total Cost: $0.04 across 17 requests
- Total Savings: $0.05 (59.1% saved)
- Average Cost/Request: $0.0022
- Lower Tier Routes: 6 of 17 (35% of requests avoided Frontier)
The savings calculation compares actual cost against a hypothetical scenario where every request uses the Frontier model at $5/$15 per 1M tokens.
API Design#
The router exposes an OpenAI-compatible chat completions endpoint, making it a drop-in replacement for existing integrations:
# Standard OpenAI-compatible endpoint POST /v1/chat/completions { "messages": [{"role": "user", "content": "Hello!"}], "stream": true # Streaming supported } # Model is auto-selected. Or specify one: { "messages": [...], "model": "gpt-4.1-mini" # Override auto-routing }
Additional endpoints for routing insight:
POST /api/routing/preview # Preview routing without executing GET /api/analytics/costs # Cost breakdown by tier/model GET /api/analytics/savings # Savings vs. frontier-only GET /api/budget # Current budget status PUT /api/budget # Update budget limits GET /health/ready # Full dependency health check
Deployment#
The entire stack deploys with a single command via deploy.sh:
./deploy.sh deploy
This runs a 6-phase pipeline:
- Terraform provisions Azure Foundry (AI Services), Redis Cache, Cosmos DB
- Azure Container Registry creation and configuration
- Docker builds for both backend and frontend (linux/amd64)
- Image push to ACR
- Backend Container App deployment (0.5 CPU, 1GB RAM, 1-10 replicas, port 8000)
- Frontend Container App deployment (0.25 CPU, 0.5GB RAM, 1-5 replicas, port 80)
Environment variables are injected at deploy time: Foundry credentials, Redis URL, Cosmos endpoint/key, and the backend URL for the frontend.
For local development, docker-compose up spins up the backend, frontend, and a local Redis instance.
Key Design Decisions#
Why keyword-based classification instead of ML? An ML classifier would need its own inference call, adding latency and cost to every routing decision. Keyword matching runs in microseconds, is fully deterministic, and covers the major categories well enough for routing purposes.
Why five complexity components instead of just token count? A single metric misses important signals. "Explain the implications of quantum entanglement" is only 7 tokens but requires deep reasoning. The five-component system catches these cases through question depth and domain specificity.
Why category as a floor, not a weighted average? If a user asks a math question, routing it to GPT-4.1 Nano because the query is short would produce incorrect results. Certain categories have minimum capability requirements that should never be violated, regardless of other signals.
Why Redis + Cosmos DB instead of just one? Redis handles hot-path operations: real-time budget tracking (atomic increments), routing cache (300s TTL), and live statistics. Cosmos DB handles cold-path operations: persistent audit logs, historical analytics, and user-specific budget configurations. This separation keeps the routing path fast while maintaining full observability.
Extending the System#
The architecture is designed for extensibility:
- New Models: Add entries to
MODELSdict inmodel_config.pywith tier and pricing - New Providers: Implement the
BaseProviderinterface — slots exist for Anthropic Claude models - Custom Categories: Add to the
QueryCategoryenum andCATEGORY_TIER_MAP - ML-based Classification: Swap the keyword
SemanticRouterfor an embedding-based classifier without changing the routing pipeline - Per-User Routing: The budget system already tracks per-user; routing rules could be customized similarly
Conclusion#
Intelligent model routing is one of the highest-leverage optimizations for LLM-powered applications. By analyzing query complexity and category before selecting a model, you avoid overspending on simple tasks while preserving quality for complex ones.
The system demonstrated 59% cost savings on a real workload with zero degradation in response quality — simple queries got faster responses from lighter models, and complex queries still received Frontier-tier reasoning.
The full source code, Terraform configs, and deployment scripts are available in the repository. Deploy it with ./deploy.sh and start routing.